《BGP设计与实现》读后感及总结之3
第7章:可扩展的IBGP设计和实施指南
如果不优化IBGP session,那么在大型网络中不仅会对设备性能及内存造成影响,庞大的配置对于管理人员也是头疼的事。路由反射器和联盟就是有效地解决方法。路由反射器是对一定类型的路由器放松IBGP环路防止机制,而联盟是把大的AS分成许多小的AS。
1. RR只反射每条前缀的最佳距离,并且不会修改常用属性,如next_hop,as_path,local_pref和med
2013-1-25 更新:VNH技术
在电信中,冗余的设计保障了业务的可靠传输,对于域间BGP可以用BGP的负载均衡,但是在域内由于路由都是靠RR反射的,所以对不同汇聚设备上来的路由到RR后,RR只会反射一条最优的,这样就导致只有一个汇聚设备可达,为了避免这个问题,会用到VNH技术,就是强行通过Policy在路由发送到RR前把BGP的下一跳改为同样的,这样RR反射后,其他设备就只会到这个地址。同时为了让这个不存在的下一跳可达,在做Policy的设备上设置静态并充分发到整个ISIS域中,这样就把BGP的负载工作交给IGP来做了,可以尽量优化流量不均的问题,如下图所示,另外对于IBGP的负载,稍后再确认下

2013-8-19 更新:解决IBGP只发最优路径的其他解决方法
如上说的VNH只是其中一种方法,其实还有几种方法可以优化IBGP多路径,下面来逐一说明:
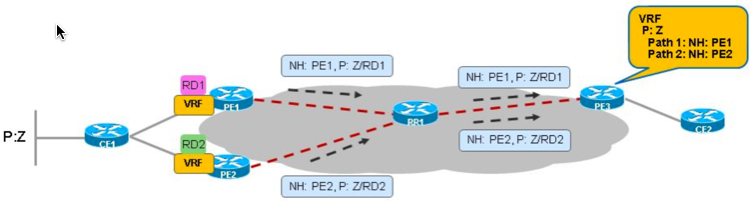
1. 利用RD来实现多路径,由于在MPLS VPN的环境,前缀都是同RD一起发送的,所以当某个用户multi-home时,把两个PE上的相同VRF改成不同的RD,这样RR收到路由更新就认为时两个不同的更新,所以两条路径都会发送,但这只能当时MPLS的环境才适用,如下图所示:
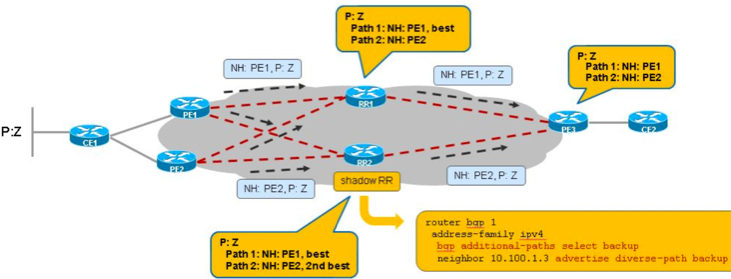
2. Shadow RR,给主RR找个“备胎”,主RR转发一个路径,Shadow RR转发另一个路径,但这种方法限制多多,比较麻烦,还要另增加一个RR,具体可以参考《BGP Diverse Path Using a Diverse-Path Route Reflector》可以参考下图:
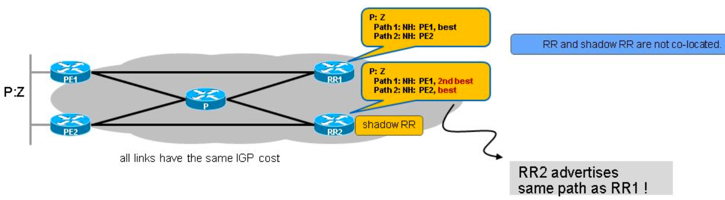
shadow RR只会发送backup的路由,另外BGP路由都会递归到IGP的metric,因此IGP的改变可能会影响shadwo RR的部署,所以最好关闭“bgp bestpath igp-metric ignore”,影响如下所示,由于IGP metric的关系,导致两个RR分别选择了不同的两个,但由于shadow的关系,shadow RR会发送另一个backup的路由,这样问题就会发生了:
3. 用BGP Additional Paths这个feature,也可以实现类似的功能2019-5-27-update:
正好有个机会,在IPv4的环境下想把多个peer的路由都收下来,测试了下additional path,简单summary到这里,以备后面review:
RR的配置:
RP/0/0/CPU0:RR#sh run router bgp Mon May 27 02:49:53.653 UTC router bgp 100 bgp router-id 192.168.0.7 bgp cluster-id 192.168.0.7 address-family ipv4 unicast additional-paths receive additional-paths send additional-paths selection route-policy RR-PIC ! neighbor-group client remote-as 100 update-source Loopback0 address-family ipv4 unicast route-reflector-client ! ! neighbor 192.168.0.1 use neighbor-group client ! ...... RP/0/0/CPU0:RR#sh run route-policy RR-PIC Mon May 27 02:50:34.302 UTC route-policy RR-PIC set path-selection backup 1 advertise end-policy RP/0/0/CPU0:RR# RP/0/0/CPU0:RR#sh bgp Mon May 27 02:51:07.818 UTC BGP router identifier 192.168.0.7, local AS number 100 ...... Status codes: s suppressed, d damped, h history, * valid, > best i - internal, r RIB-failure, S stale, N Nexthop-discard Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path * i10.1.1.1/32 19.1.1.9 0 100 0 900 i *>i 192.168.0.4 0 100 0 1000 i * i 192.168.0.5 0 100 0 1000 i RP/0/0/CPU0:RR#sh bgp 10.1.1.1/32 det Mon May 27 02:51:23.897 UTC BGP routing table entry for 10.1.1.1/32 Versions: Process bRIB/RIB SendTblVer Speaker 9 9 Flags: 0x00003028+0x00010000; Last Modified: May 27 02:21:29.832 for 00:29:54 Paths: (3 available, best #2) Advertised IPv4 Unicast paths to update-groups (with more than one peer): 0.2 Advertised IPv4 Unicast paths to peers (in unique update groups): 192.168.0.1 Path #1: Received by speaker 0 Flags: 0x4000000000020205, import: 0x20 Not advertised to any peer 900, (Received from a RR-client) 19.1.1.9 (inaccessible) from 192.168.0.1 (192.168.0.1) Origin IGP, metric 0, localpref 100, valid, internal Received Path ID 0, Local Path ID 0, version 0 Path #2: Received by speaker 0 Flags: 0x4000000001060205, import: 0x20 Advertised IPv4 Unicast paths to update-groups (with more than one peer): 0.2 Advertised IPv4 Unicast paths to peers (in unique update groups): 192.168.0.1 1000, (Received from a RR-client) 192.168.0.4 (metric 500) from 192.168.0.4 (192.168.0.4) Origin IGP, metric 0, localpref 100, valid, internal, best, group-best Received Path ID 0, Local Path ID 1, version 7 Path #3: Received by speaker 0 Flags: 0x4000000000060205, import: 0x20 Advertised IPv4 Unicast paths to peers (in unique update groups): 192.168.0.1 1000, (Received from a RR-client) 192.168.0.5 (metric 501) from 192.168.0.5 (192.168.0.5) Origin IGP, metric 0, localpref 100, valid, internal, add-path <<< Received Path ID 0, Local Path ID 2, version 9 RP/0/0/CPU0:RR#show bgp nei 192.168.0.1 | i Additional-path Mon May 27 02:53:30.108 UTC Additional-paths Send: advertised Additional-paths Receive: received Additional-paths operation: SendClient的配置
注意Client配置完后需要clear下,在对端clear不会生效的;
RP/0/RP0/CPU0:R1#sh bgp Mon May 27 02:45:13.008 UTC BGP router identifier 192.168.0.1, local AS number 100 ...... Status codes: s suppressed, d damped, h history, * valid, > best i - internal, r RIB-failure, S stale, N Nexthop-discard Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path *> 10.1.1.1/32 19.1.1.9 0 0 900 i * i 192.168.0.4 0 100 0 1000 i * i 192.168.0.5 0 100 0 1000 i <<< RP/0/RP0/CPU0:R1#sh run router bgp Mon May 27 02:58:35.342 UTC router bgp 100 bgp router-id 192.168.0.1 address-family ipv4 unicast additional-paths receive <<< additional-paths selection route-policy pic <<< RP/0/RP0/CPU0:R1#sh run route-policy pic Mon May 27 02:59:20.342 UTC route-policy pic set path-selection backup 1 install end-policy !4. 用Best External这个feature,也可以,详细看《BGP Best External》
总结:
感觉还是VNH比较好,不用这么多配置,管理维护也方便,其它几种方法没有测试过,有时间测试下再讨论。
2. RR不会把它从IBGP对等体学来的前缀通告给另一个非客户。
3. 分簇是给RR提供冗余的,如果多台RR的cluster_id(通常是BGP的RID)相同,那么它们属于同簇,RR之间不能互相通告前缀。

4. 在没有RR的环境IBGP学到的前缀不会发给另一个IBGP,因此可以防环,而RR是把前缀从一个IBGP反射给另一个,所以如果有多个RR,可能会有潜在的环路问题,这种情况下可以用到两个feature防止环路,一个是cluster_id,另一个是originator_id,两种都用的RID表示。如图所示,当R5是客户或非客户时,会用到originator_id, 这个id是当R5把前缀更新给RR,RR反射给客户和非客户时打上的,ibgp都会check这个参数。换言之,RR会对前缀打上本AS首发IBGP路由器的RID;当R5是RR时,他会把RID装入cluster_id中,RR会去check这个参数:

下面show的路由是从R4发出经过rr反射给R3的:
R4–ebgp–(R1—-R2(rr)—–R3)
R3#sh ip bgp 172.15.0.6
BGP routing table entry for 172.15.0.6/32, version 10
Paths: (1 available, best #1, table Default-IP-Routing-Table)
Not advertised to any peer
200
12.1.1.1 (metric 2) from 23.1.1.2 (172.15.0.2)
!---"12.1.1.1"是这条bgp路由的下一跳,这里是R1
!---"metric 2"是这个下一跳在igp中德metric
!---"23.1.1.2"这个bgp是谁发来的,这里是R2
!---"172.15.0.2"发bgp路由的RID
Origin IGP, metric 0, localpref 100, valid, internal, best
Originator: 172.15.0.1, Cluster list: 172.15.0.2
!---"172.15.0.1"在本AS中,R1最先转发该路由给RR,因此RR把R1的RID打在Originator上
!---"172.15.0.2"这个路由只经历了一个RR,所以只有一个RR的RID
5. 层次化RR,不是特别理解,介绍的也不是非常多。。。
6. 设计RR时遵循原则之:为了保持逻辑拓扑和物理拓扑的吻合以防止环路,可以从下面几种方法解决
-遵循物理拓扑
-RR和非客户之间的会话不应该穿过客户
-RR和他的客户之间的会话不应该穿过非客户
7. 设计RR时遵循原则之:使用可比较的AS间的度量,由于路由在IOS学习会按照时间顺序排列,然后从上往下对比(最上是老路由,最下是新路由),所以不统一的度量,很可能造成环路(如何产生环路,请看书),通过“always-compare-med”、“derministic-med”或清除入境的med都可以解决这个问题,书上有详细的例子。关于这两条命令,可以查看《CCIE SP — BGP 13条选路原则》
9. 设计RR时遵循原则之:设置适当的IGP度量,原因同上,解决的方法是簇内的度量要比簇间的度量底,这使RR优先选择簇内而不是簇间路径,设计路由选择的问题,内容多,详细看书。
10.设计RR时遵循原则之:分簇设计,防止同簇不能互相通告的。如图所示,如果是同簇的,RR之间不会相互通告,那么当R3和R4之间的链路down时,R1只能通过R2到达R5,R1和R3的link相当于摆设;如果分簇设计,遇到同样的问题,R1和R3的仍然会利用上,这样可以避免ISP内部问题而导致客户的路由问题。但这种部署比起同簇来说,显然要占用更多资源,管理起来更复杂。

11.设计RR时遵循原则之:含有对等组的RR。在老期的IOS中,RR不能使用对等组,因为当RR收到前缀更新后,会向整个group进行withdraw,这样导致其他路由器清楚这条路由,除非其他路由器跟更新路由器全连接。现在大部分的IOS中,都已经做了优化,当收到前缀后,RR不会再发送withdraw,而是向所有客户或非客户反射更新,包括发送更新的客户,发送更新的客户收到RR发的更新后,发现originator_id是自己的,就会drop这个更新。
12.联盟对于RR是另一种解决BGP扩展性问题的方法,在使用联盟时,AS_PATH做了特殊的处理,可以对子自治系统进行防环,如下图所示:

13.在联盟中的团体属性也进行了特殊处理,如下图所示:

14.如果IGP很大,那么可以用联盟分割IGP,以扩展IGP;但是更多ISP部署RR而非联盟;对于联盟的管理相对较复杂。
以下为2013-3-27日更新
———————————
第8章:路有反射器和联盟迁移策略
对于迁移,中心思想就是保证业务尽量不被影响,出发点可以从核心,接入及eBGP对等这几个角色出发,根据冗余情况来定。根据书中提到的案例,适合从核心出发因为有足够的冗余,当然当割接到带业务的路由器,肯定是要影响业务的。
1. 从iBGP全连接迁移到RR
由于不改变AS号,所以比较容易实施,最终4个RR全互联。

第1步:选择核心R4入手,设立RR client 组
第2步:准备把R4从全互联切换到RR,为了避免以R4为BGP下一跳的业务受到影响,这里增大R4链路的IGP metric,保证BGP的下一跳不会选R4为下一跳(还有其他2种方法,详细看书)。metric更改后,业务就会绕过R4,这时更改R4配置,对R6和R7应用client组。此时对于业务路由,R6和R7分别收到了两个方向的,一个是始发的,另一条是R4反射的,优选始发的(路由信息看书)。
第3步:清除调整的IGP metric,业务又开始从R4走。
第4步:选择R5,重复1,2,3。
第5步:拆掉R4,R5,R6和R7不用的配置
第6步:对另一个POP点,重复1-5。
2. 从iBGP全连接迁移到联盟
由于涉及联盟,所以AS号会变更,这样比起上面那种情况,要复杂的多
第1步:同样选择R4,改metric,把R4从路径中移除
第2步:清掉原有BGP,建立BGP联盟,为了冗余,在其他设备上也配置联盟。
#bgp router 65001
#bgp confederation identi 100
#bgp conf peers 100 65000
另外在新配置中分两部分,一部分是与联盟内路由器的iBGP关系,另一部分与R1和R2的eBGP关系,此时R4不再与R3建立关系。
第3步:在R1和R2上更新与R4的eBGP配置,由于改成联盟后,在联盟内存在iBGP和eBGP,所以会涉及下一跳的问题,不建议使用next-hop-self(问题如下面红色注释),建议使用IGP来选择下一跳。书中是把R1与R8的直连路由重分发到IGP中了。
第4步:把R6移到联盟,只与R4的关系是激活的,R5和R7还没OK,不与R1,R2和R3建立关系,此步骤会影响R6上的业务。完成后清除R4的metric,放回到转发路径中,R8可以访问R6。
注意:对于前面说的,为什么不建议使用next-hop-self,拿R1和R4的eBGP来说。如果设置了,对于R4来说,R3,R8和R7的路由都是通过AS100学到,下一跳为R1。而对于R1来说,到达R7的下一跳为R4或R5(IGP递归),因为此时R4已经被放回到转发路径中,所以就形成了潜在的环路,换言之,BGP和IGP是独立的,当BGP的下一跳不是“C”路由时,会递归到IGP中查找。如图所示:

第5步:把R7迁移到联盟中,R7只与R4,R5,R6建立关系。并把R5从转发路径中移除,迁移R5到联盟中,成功后放回到转发路径中。与R4同理,不能在R1上对所有peer设置next-hop-self。
第6步:更新R1和R2对R5的配置,并移除与R6和R7的无用配置。至此右边的POP点完成迁移。
第7步:用同样的方法迁移左边的POP点。
3. 从RR到联盟
这个跟从iBGP到联盟差不多。
第1步:R4为起始,移出转发路径,配置联盟,建立新的iBGP和eBGP关系。并用联盟配置更新其他路由器。
第2步:更新R1和R2的对等关系,注意同上,如在R1上用next-hop-self,会有潜在环路。仍采用重分不R1与R8的直连,使联盟内路由器可达。
第3步:把R6移到联盟中,建立新的iBGP关系,并把R4移回转发路径。
第4步:把R7移到联盟中,建立新的iBGP关系,并把R5移出转发路径。

第5步:把R5移到联盟,建立iBGP和eBGP,并把R5移回转发路径。更新R1和R2的配置。
第6步:用同样的方法迁移左POP点。
4. 从联盟迁移到RR
第1步:R4为起始,移出转发路径,建立新的iBGP和eBGP关系(RR),为了冗余,仍然带着联盟的配置。
第2步:更新R1和R2的对等关系
第3步:把R6移到RR环境中,建立新的iBGP关系,并把R4移回转发路径。
第4步:把R7移到RR环境中,建立新的iBGP关系,并把R5移除转发路径。
第5步:由于步骤都差不多,没有什么要注意的,就不再此介绍,详细看书吧。
第9章:服务提供商网络架构
从宏观介绍了ISP的分类,另外包含了一些有用的配置模版,和策略模版,用时可以回来查查。
1.一些基本的概念
书中介绍了对于ISP的穿越和对等的概念,谈到这个就要说下ISP的级别,这里面穿越和对等的价钱可以是不一样的。
Tier1:
国家范围骨干网
没有购买任何穿越服务
完全依赖于对等关系
Tier2:
国家范围骨干网
由对等和穿越组成
Tier3:
区域网络或本地网络
几乎完全依赖于穿越服务
也许有一些对等关系,当通常没有
2. BGP的安全特性
-为了防止攻击,对BGP会话应用TCP MD5
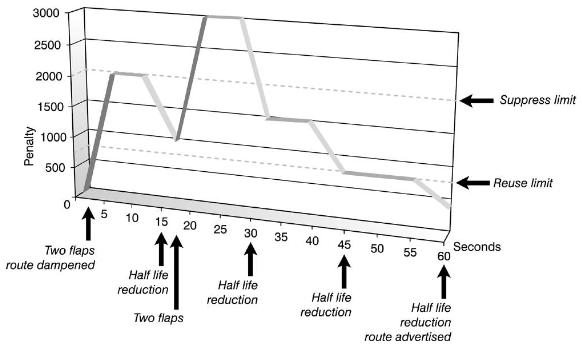
-分级路由抖动damping,不是对整个neighbor,而是根据重要程度对具体的路由执行不同的damping策略,如下所示:
router bgp 100
bgp damp route-map testroute-map test per 10
match ip address prefix-list xxx
set dampening 10 1500 3000 30half-life:分钟,如果10分钟后路由稳定,惩罚值减少一半(默认15min)
reuse:惩罚值低于1500后,取消抑制(默认750)
suppress:抑制阀门,超过这个,路由被抑制(默认2000)
max-suppress-time:最大抑制时间(默认60min,4倍的half-life)
当路由前缀被撤销时,BGP认为此路由在波动,于是增加1000个惩罚点;当BGP收到属性变化的前缀时,增加500点。
2013-6-24 更新:
bgp dampening 只对EBGP学习过来的路由起作用,对IBGP不起作用。他使用来抑制一些频繁震荡的路由,它不能阻止一个路由器接收不稳定的路由,但是它能够阻止公布不稳定的路由。
被抑制的路由会被标记上suppressed。
下面的图来自《路由设计优化》,看着更形象:
3. 公共对等体的安全
故名思义,在公共对等体上链接着很多ISP,对于不守规则的小ISP,可能会钻这个空子,通过种种方法让流量走其他的ISP,这样可以省很多钱。下面是几个窃取方式:
-指向默认路由
如图所示,由于NAP比穿越便宜,所以ISP1指默认路由到ISP2,这样ISP1的出流量就得由ISP2来承担费用,预防方法就是在ISP2的NAP路由器上不要放全路由。

-指第三方下一跳
如图所示,正好跟上面的相反,在ISP1发布路由的时候把下一跳改为ISP2,这样进流量就会从别ISP2绕过来,省了ISP3到ISP1这段的对等费用。预防方法同上,在ISP2的NAP路由器上不放全路由。

-建立GRE隧道
这种比较简单,如上图,ISP1和ISP2下边的peer也是NAP,这样ISP1通过直连eBGP来建立GRE,预防办法就是不要在NAP的路由器重分发eBGP的直连路由到IGP,没有路由,GRE就建立不起来了。
4. 缓解分布式DDOS攻击
2019.12.9号更新1:
其实下面解释的就是基于目的地址的RTBH (Remotely Triggered Black Hole Filtering )
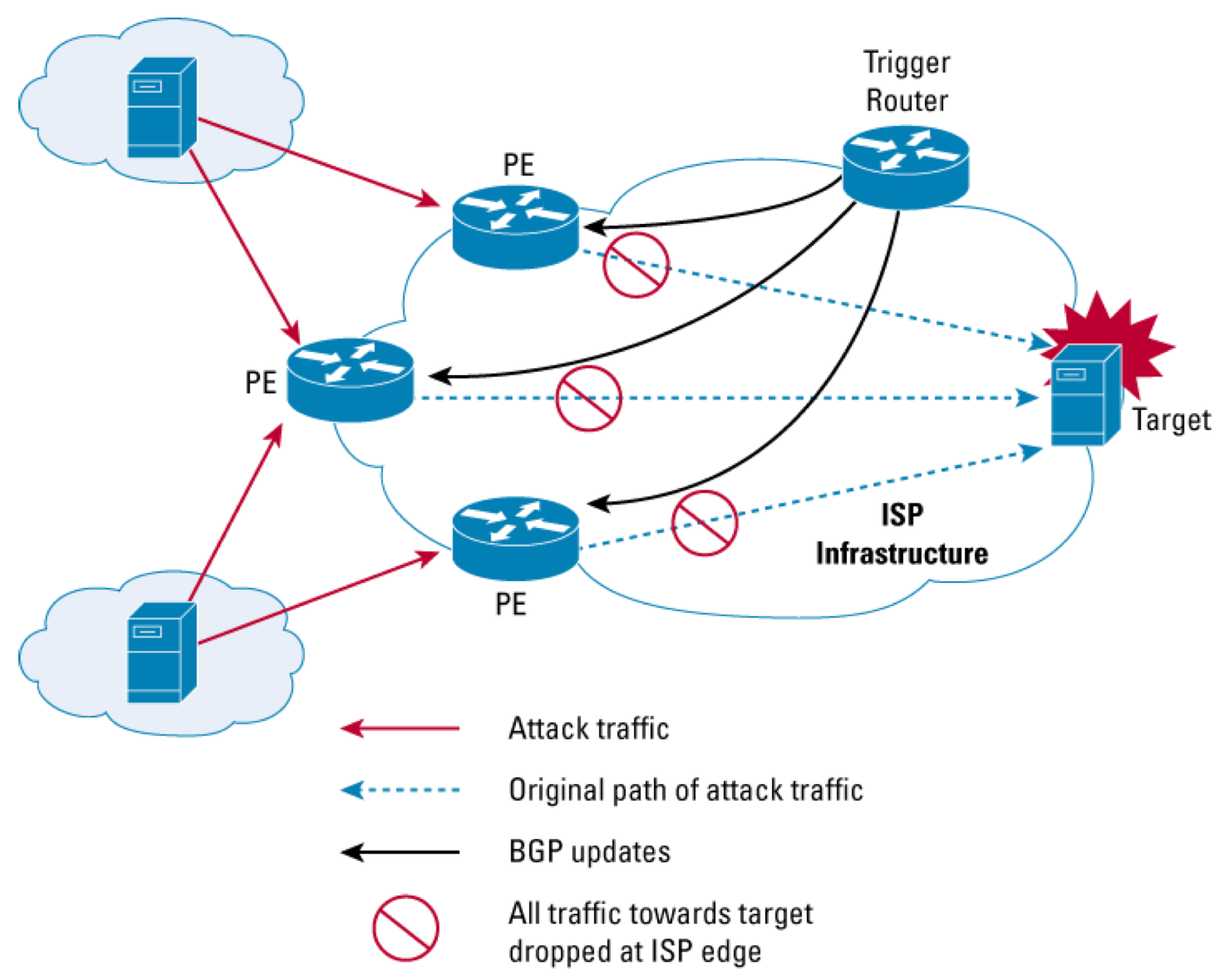
在ISP中常见预防DDOS攻击的方法是在受攻击的路由器上指一条null路由,如果是分布式的DDOS攻击,这种方法显然不是很方便,所以用下面方法把null路由通过BGP通告给网中的所有设备。下面是在每台边缘路由器上配置。
ip route 192.0.2.0 255.255.255.0 null0
!
router bgp 100
redistri static route-map ddos
!
route-map ddos per 40
match tag 999
set ip next-hop 192.0.2.1
set community no-export
set origin igp
!
route-map ddos per 50
match tag 998
set community no-export
set origin igp
!
route-map ddos deny 60
用tag标识比prefix-list方便的多,如当220.220.220.220受到攻击了,只需配置:
ip route 220.220.220.220 255.255.255.255 null0 tag 999
如果需要分析这些攻击流量,提前把分析仪的地址公布到IGP中,如下192.168.1.1就是分析仪:
ip route 220.220.220.220 255.255.255.255 192.168.1.1 tag 998
不在ddos策略中直接指分析仪下一跳是因为可以通过这种方法灵活的把不同的攻击流量指向不同的分析仪上。
2019.12.9号更新2:
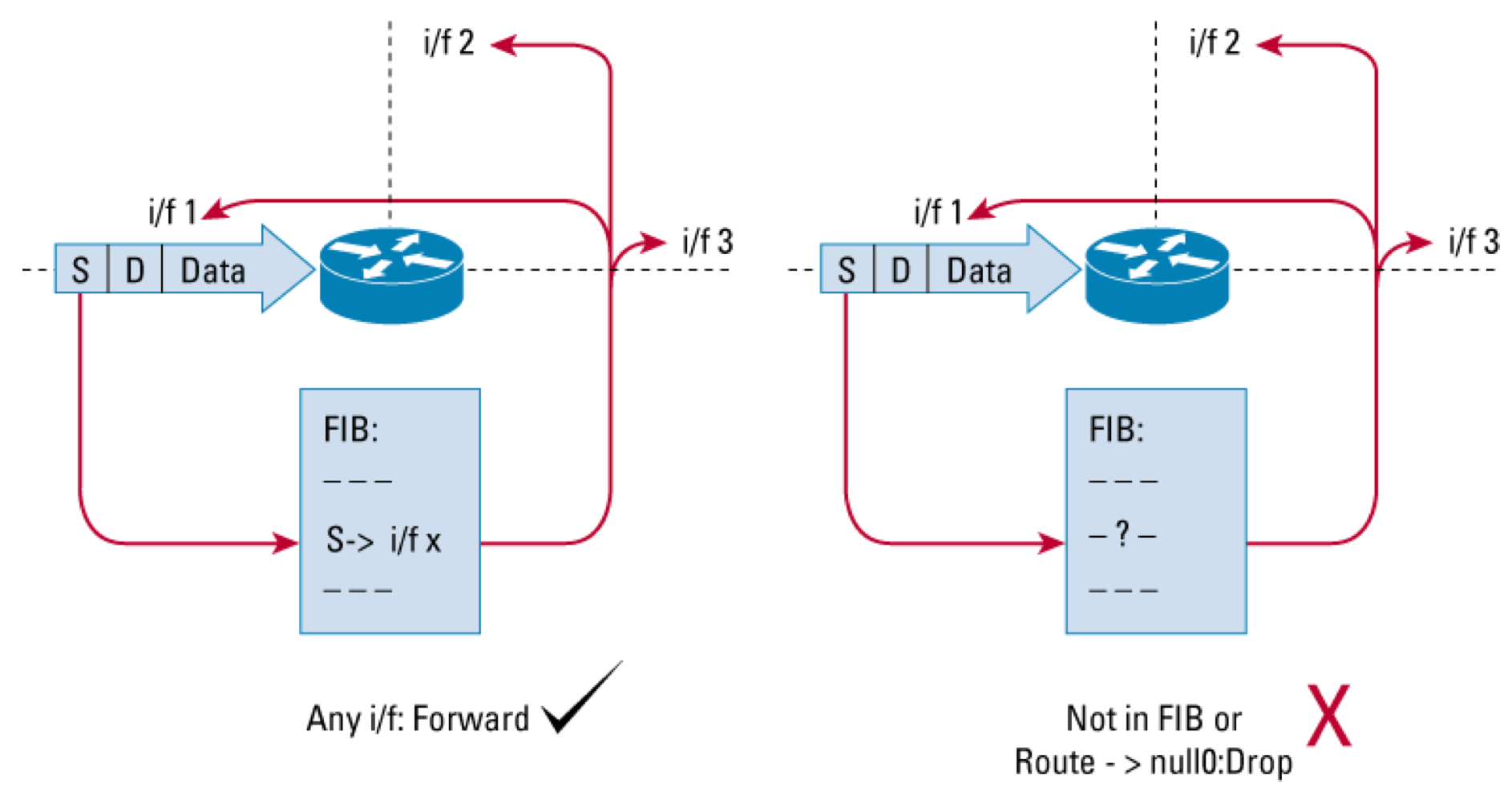
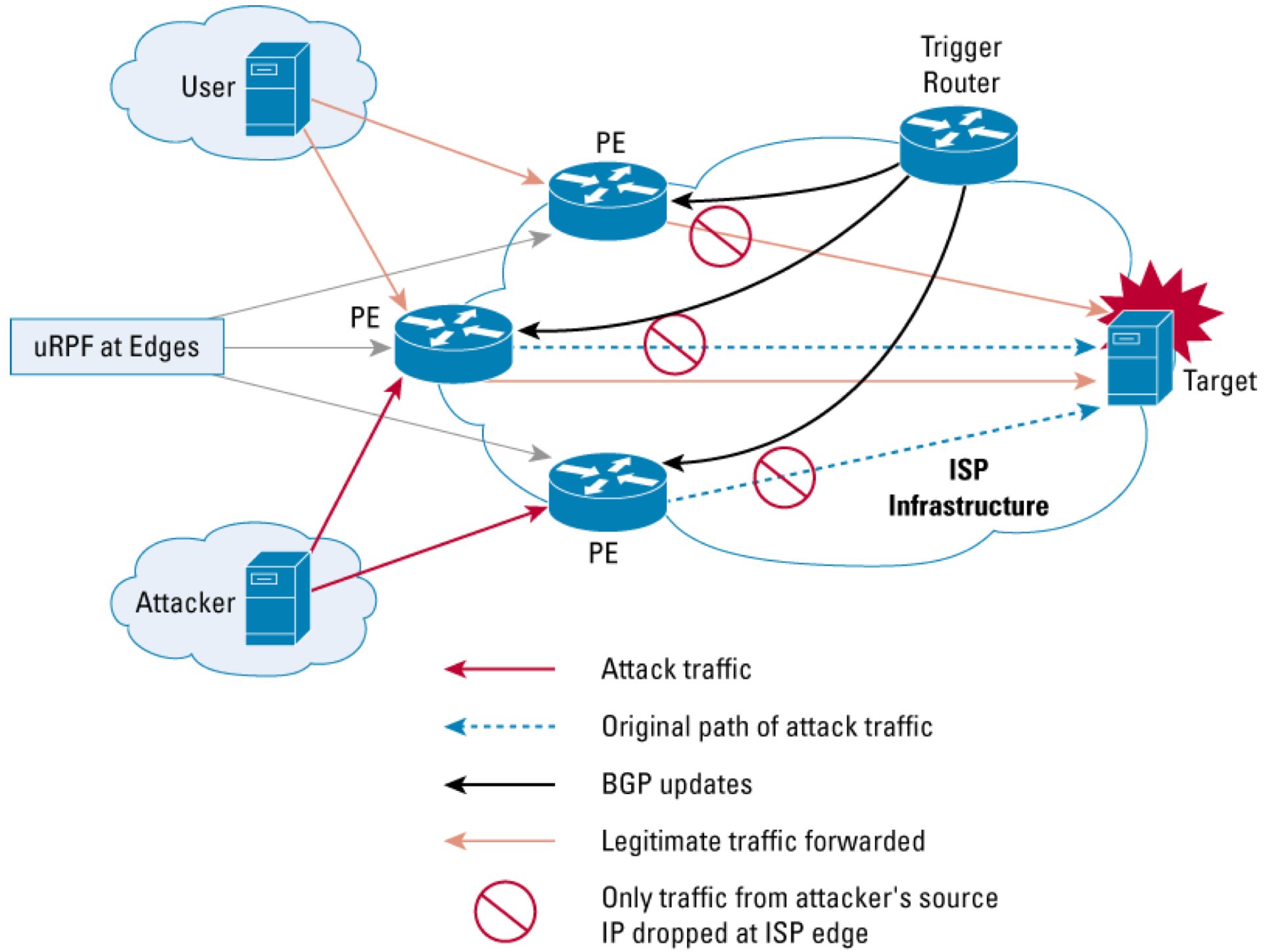
基于目的的RTBH,会把所有到目的地的流量都drop掉,这里面包含合法和非法流量,如果基于源的RTBH,那么可以只把非法流量drop掉。基于源的RTBH需要跟Loose URPF配合使用,Loose URPF确认数据包原地址是否有回程路由,有的话转发,没有就drop(null0属于没有),如下图:
下面是基于源的RTBH示意图:
跟destination类似,先找到攻击源,然后在trigger上发布的静态路由指向攻击源,下一跳为null0,通过iBGP发布到所有PE,这个路由会导致uRPF check失效,实现drop非法源流量的目的
原始文档在这里:rtbh-blackhole
2013-8-30 更新:BGP TTL Security
昨天跟同事讨论了下BGP TTL security check 和 BGP multihop 这两个feature的区别,看上去功能都差不多,就是限制了协商的跳数,但这两个feature有着本质的不同,那就是multihop无法防止DDOS攻击,而TTL Security check是可以防止DDOS攻击的。这里说的DDOS攻击就是BGP peer攻击,换句通俗的话说,我们可以用认证防止非法连接,是短时间大量认证请求,会导致路由器的CPU Peak,并且还可能导致BGP crash,从而影响设备重启(IOX下BGP crash不会导致设备重启)。BGP的默认行为是只允许直连建立peer,也就是发送的TCP TLL是1,到达对端后就变成0了。可以用multihop改变这种行为,实现多跳建立,但它改变不了TTL的行为,这就导致BGP还是会受到攻击(如何攻击看下文)。
而Multihop这个TTL Security check改变了TTL的行为,使其发送TCP请求时,TTL为255,当对端收到后,如果设置的hop为2,那么对端只接收>=(255-2),小于253的都不接受。对于攻击者而言,他发送的攻击报文始发的最大TTL是255,遇到中间设备就会减一,不受攻击者控制,导致到达攻击目标后,TTL要远远小于253。
这里有Jeff Doyle大神的解释:
http://www.networkworld.com/community/node/18760
请大大详解一下VNH 附图 感谢!
填上去了,你可以参考下。
解决IBGP只发最优路径的其他解决方法..还是觉得Additional path好哦:)