论文总结:Resilient AI Supercomputer Networking using MRC and SRv6
距上次梳理阿里HPN的论文已过去2年时间了,这次看微软/OpenAI联合多家NIC/交换机厂商(NV CX-8、AMD Pollara/Vulcano、BRCM Thor Ultra、NV Spectrum 4/5、BRCM TH5)发布的 MRC + SRv6 论文,网络架构思路差异很大,但很多设计点跟HPN/UEC形成对比,值得对照仔细研究,里面很多信息可以借鉴和参考,可以说是为数不多的好论文(对我的领域而言)。从目前的形式看,业界有从 Lossless RDMA -> Lossy RDMA 转向的趋势,目前国内看到的阿里已经大规模部署Lossy RDMA,字节去年也发布了他们自己的Lossy RDMA方案,UEC里的UET也是定义在Lossy以太网中,现在MRC又拱了一把火。
在论文中,MRC把应用层的多路径(1 collective 拆多 QP,每 QP 经 ECMP 一条路径)下沉到transport层,对应用透明。而且把大量网侧的功能下沉到NIC,完全由NIC来完成。虽然规避了一些问题,但也带来了tradeoff,使应用场景受限。而对于网侧来说,除了要支持SRv6和Packets Trim外,就是傻大快了。当然决定架构走向的往往不是技术本身。
注:以下纯属个人分析,很多内容是根据论文推出来的,权当自己的阅读笔记,留作日后 review。理解难免有偏差,若有错漏之处,恳请留言指正,不胜感激。
论文原文:
MRC Spec:
拓扑
同阿里,也是2层架构。主要差别是采用了4/8多平面,而非阿里的双平面。对于多平面的架构,Deepseek在2025年底的论文 Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures 中提到过类似架构,1个GPU对1个NIC,然后每个NIC在单独的平面内:
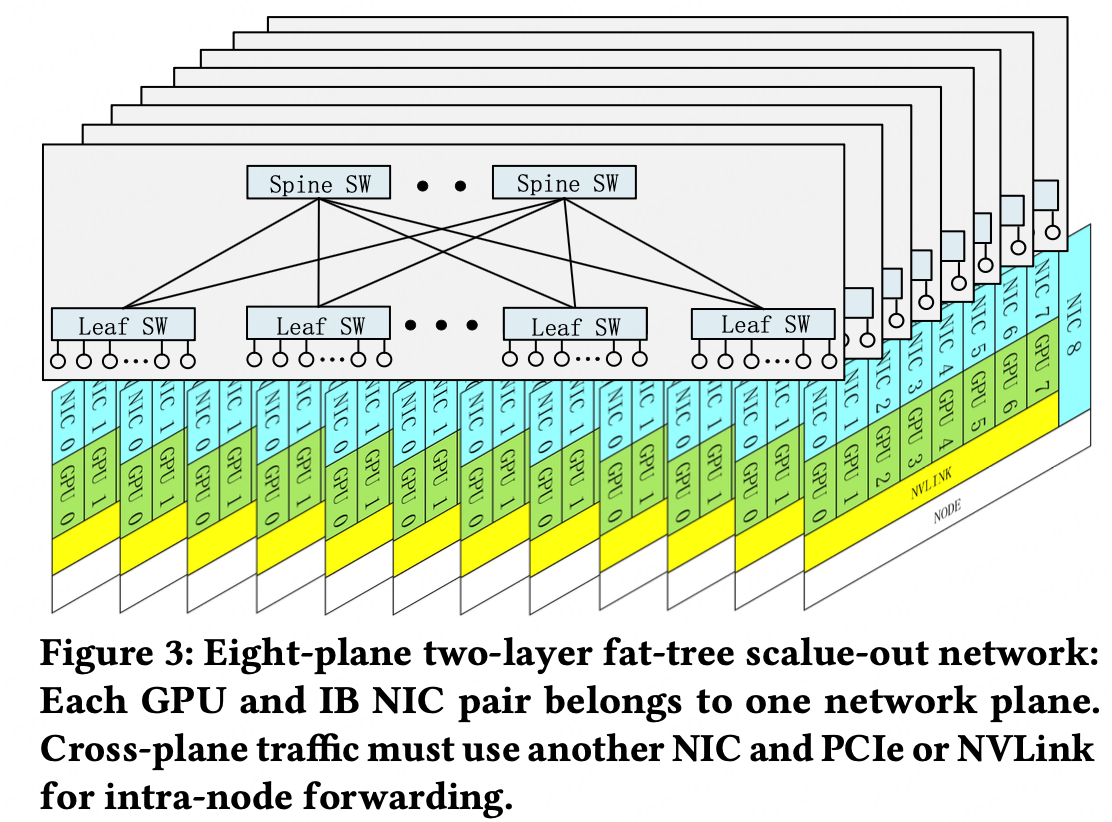
Furthermore, due to the current limitations of IB ConnectX-7, our deployed MPFT network does not fully realize the envisioned architecture. Ideally, as depicted in Figure 4, each NIC would feature multiple physical ports, each connected to a separate network plane, yet collectively exposed as a single logical interface to the user through port bonding.
而在MRC的架构中,则是把每个NIC连4平面或8平面上而非单平面,具体看需要的规模而定。这样相当于是在Deepseek的架构之上又翻倍了集群规模。去年听说OPENAI在要512*100g,但当时BRCM的51.2还有些问题,所以又重新留了一个片子以支持这个需求。当时特意画了下预期的网络架构图,现在看来同他们论文中的完全吻合,131072卡:
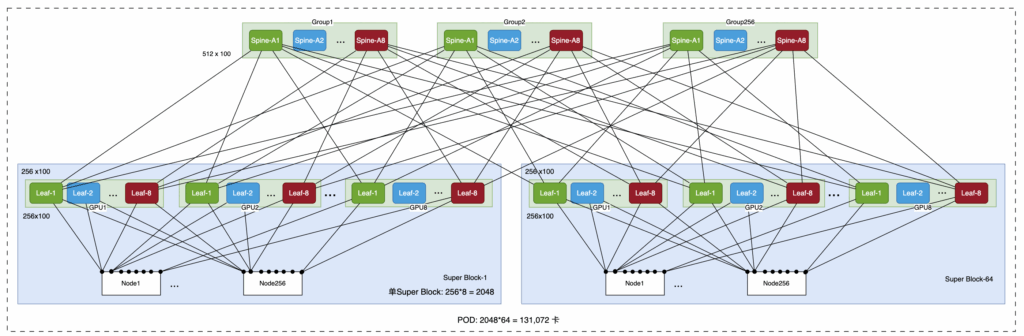
组网规格及物理实现
论文提供了4种:
| Cluster | NIC | Switch | 拓扑 |
| A | NV GB200 + CX8 (800Gb/s) | NV SP4 & BRCM TH5 | 2-Tier 4×200G 多平面 |
| B | NV GB200 + CX8 (800Gb/s) | NV Spectrum 5 | 2-Tier 8×100G 多平面 |
| C | AMD MI355 + Pollara (400Gb/s) | BRCM TH5 | 2-Tier 4×100G 多平面 |
| D | NV RTX 6000 + BRCM Thor Ultra | BRCM TH5 | 2-Tier 400G 单平面(测试床) |
但不管哪种组网规格,物理形态均为:
- 网卡是800g*1 or 400g*2
- 交换机是64*800g
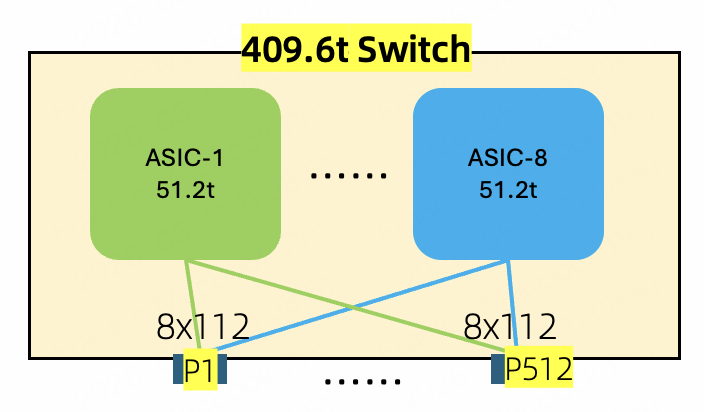
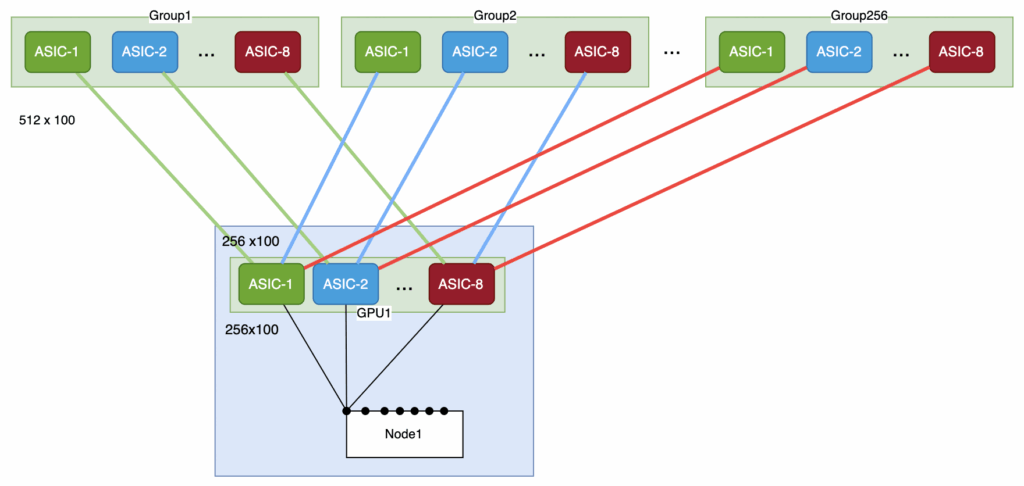
因此在这种形态下,要想分平面互联,只能使用patch pannel。虽然2-Tier降低了光模块和交换机的成本,但增加了光纤的数量,提升了互联的复杂性,维护成本上升了。除非后面把4平面或8平面的设备都放到一个盒子里合并互联,来简化互联复杂性,如下面方式(只是举一个例子,把8个51.2放到1个盒子里,有很多挑战,但4个51.2还是有可能的),但这会带来SONIC如何适配多芯片的难题:
Plane 和 Path 数量
只针对Cluster B分析,单 Plane:
- T0:512 台 x 256 NIC 下行
- T1:256 台 x 512 T0 下行
- 单 Plane 内 1个T0_src -> 1个T0_dst path 数 = 256 (经 256个 T1),注:dst GPU固定后,T1 ->T0_dst 只有1个path
8 Plane:总 path 数 = 2048
故障 blast radius
T0 端 OSFP 抖 → 影响 8 个不同 node 各 1 个 100G plane(每个 node 还有 7 个 plane 在跑,业务可继续)
NIC 端 OSFP 抖 → 影响该 NIC 所有 plane → QP fail
协议层
协议层是MRC(Multipath Reliable Connection)是此论文的核心,是对RoCEv2 RC的增强。可以说论文中的很多方法和妥协都是围绕MRC展开的。
核心特性
- Verb API 兼容 RoCEv2(但只支持 write / write-with-immediate)
- Lossy RDMA(PFC OFF)
- Packet spraying(per-packet level, 不是 per-flow)
- Selective retransmission(SACK/NACK,非 Go-Back-N)
- Packet trimming(区分拥塞丢 vs 链路坏,同 UEC)
- ECN 仅作 LB 信号(last hop 关 ECN)
刚开始看论文时很好奇,CX8竟然可以跟TH5开Packets Spray,难道NV终于低头了?自己解开了CX8与Spectrum的绑定?但看完论文才发现,这里的Packet Spray 跟NV的方案完全不一样,相当于直接在端侧Spary,而非网侧Spray,这样自然就解耦了。
EV (Entropy Value) Set 机制
EV:32-bit path selector,carry 在 UDP src port + IPv6 flow label;EV bit 分配(示例,具体分配论文未细说):[3 bit plane | 8 bit T0 uplink | 21 bit entropy/reserved]
Active EV set per QP:128 ~ 256 个
- 8 plane 均分 → 16~32 EV/plane
- 单 QP 覆盖 path 总数: 256/2048 = 12.5%(非全覆盖)
- 多 QP 并发达到 aggregate 全覆盖 (设计 trade-off?)
Backup EV pool: 同量级,同 plane 分组
- Backup 选择算法论文未公开
- 切换不一定一次成功(新 EV 可能撞同一坏 link)
- 每次 ~10-20μs,多次叠加业务无感
Sequence vs EV — 两套独立标识
PSN(Packet Sequence Number,24-bit,应沿用 RoCEv2 BTH)→ 用于可靠传输,gap 检测,SACK
EV(32-bit,in UDP + flow label)→ 用于 path selection 和 path health 反馈
接收端用 PSN 检测丢包,用(PSN→EV)映射归因到具体 EV
故障检测机制 (μs 级,zero-cost)
数据流 piggyback 反馈,无主动 probe,如下示例:
- T=0 sender 发包用 EV_47
- T=μs 包丢 (link 坏)
- T=10-15μs 接收端 SACK gap 显示 EV_47 缺失
- T=20μs sender 标 EV_47 dead
- T=21μs backup pool 取同 plane EV 替换
- T=22μs 继续发包,业务无感
Background probe (论文未细说精度,理论秒级,极低开销):用于试探 “已踢的 EV” 是否真坏 → 复活机制
ECN – load balancing 信号(非 CC)
- 中间链路:ECN 启用 → 拥塞 path 触发 EV migration
- 最后一跳:ECN 关闭(incast 是预期的,不要 CC 干预)
- 与 UET 差异:UET 的 ECN 仍参与 CC 闭环,MRC 仅作路径信号
Packet Trimming
拥塞丢包:payload 丢,header 保留 → high-priority 转发到接收端,接收端发 NACK → sender 快重传
链路丢包 (没收到 trimmed header):视为 path failure,替换 EV
这两种丢包的区分是 MRC 反应速度的关键
路由层
论文中提供了2套方案,均兼容MRC,一套是正常的动态协议+ECMP,另一套是静态SRv6,推荐关闭动态路由。SRv6使用了USID的shift解决方案。USID对Plane、T0 uplink等相关信息进行编码,这些信息是从EV中得来,EV指定了一个确定性的path。为什么USID已经包含这些信息了,还需要EV,是因为reciver在使用NACK告知sender哪个路径有问题时,需要原始EV信息,但USID在转发过程中已经shift掉了,没有这部分信息。
而封装没有用单层IPv6,而是采用了IPv6-in-IPv6,可能有如下几个原因:
- 虚拟化 / Overlay 隔离、多租户,统一架构
- 与 host stack 的 IPv6 socket API 兼容,应用层(NCCL/MPI 等)用标准 socket API 时,不懂SRv6
禁用动态路由原因
- 大 ECMP set 在 high radix 拓扑下收敛时间长
- 路由收敛过程会扰动 ECMP mapping,这是正常操作,但会与 MRC 的 μs 级 EV 切换发生时间尺度冲突
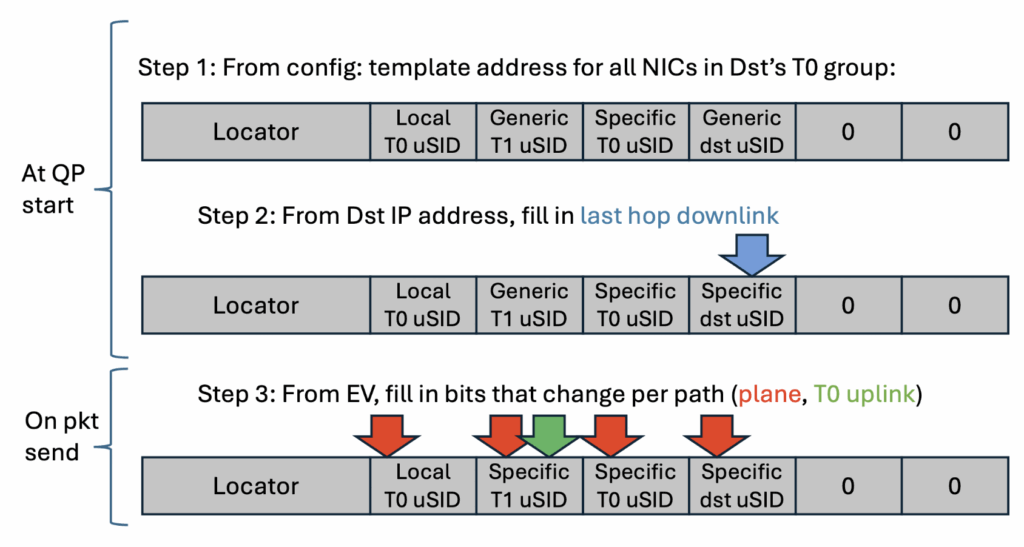
uSID 格式
外层 IPv6 destination address:
┌──────────┬──────────┬──────────┬──────────┬──────────┬───┬───┐
│ Locator │ Local T0 │ T1 uSID │T0_dst │ dst uSID │ 0 │ 0 │
│ (32 bit) │ uSID │ (16 bit) │ uSID │ (16 bit) │ │ │
│ │ (16 bit) │ │ (16 bit) │ │ │ │
└──────────┴──────────┴──────────┴──────────┴──────────┴───┴───┘
包头开销
IPv6-in-IPv6 encap 比 IPv4 RoCE 多 ~60 byte/pkt
SRv6方案有额外的包头税,但对于scale up而言,基本都是1k,4k的大包,所以增加的这些包头应该还好。
转发流程(per hop SRv6 uN)
每个交换机SRv6的转发行为:
- 比对前 48 bit(Locator + 当前 uSID)是否匹配本机
- 匹配 → left-shift 16 bit(消费当前 uSID)
- 暴露下一个 uSID → 查静态 FIB
- 出口转发
完整路径 NodeA → T0_src → T1 → T0_dst → NodeB:
- T0_src: 看到 T1 uSID → “plane=X,uplink=Y” → 出端口 Y
- T1: 看到 T0_dst uSID → “plane=X” → 单一下联到该 T0_dst
- T0_dst: 看到 dst uSID → “plane=X,downlink=Z” → 出端口 Z
- NIC: 解封装外层 IPv6,内层 IPv6 喂给 RDMA pipeline
EV → 路径 bijection
- 每个 EV → 唯一 SRv6 地址 → 唯一物理路径(确定映射)
- MRC NIC firmware 完整保有 EV→path 元数据
- 故障时切 EV = 切到完全不同的物理路径
- 但 EV 粒度是 path,不是 link → 不能定位到具体哪段坏
NIC 物理出口选择
- EV.plane → NIC 选哪个物理 100G lane (OSFP 内部)
- EV.plane → 复制到所有 uSID 的 plane field
- EV.uplink → 写入 T1 uSID
Plane bit 在 EV 里只存一份,但被复制到多处使用
运维层 Clustermapper
这个东西看上去有点Path Tracing draft (draft-filsfils-spring-path-tracing)的影子,但实现又不一样,所以应该可以理解为“path tracing 思想 + 简化的自定义协议”。
部署形态
- Agent 跑在每个 compute node 的 host userspace,而不是交换机上
- 单个 node 不需要 probe 所有 T1(2048个path),多个node能覆盖全部即可
- 论文没有提,但应该有一个中央 policy controller 汇总全网视图,然后再把denylist的数据分配给各个node使用
Probe 机制 (1 ms 级)
T0 自探针:NodeA → 直连 T0 → 回 NodeA 自己;检测 NIC-T0 link 健康 + T0 本身
T1 自探针:NodeA → T0 → T1 → T0 → 回 NodeA 自己;检测 T0-T1 link 健康 + T1 本身
优势(vs 传统 pingmesh):
- SRv6 source-routed,switch 数据面 line-rate 处理
- 不进交换机控制面 CPU
- 包送到自己,消除远端故障干扰
- 故障定位精度:区分 NIC-T0 vs T0-T1 vs T1 本身
三层时间尺度分工
- μs 级:MRC 数据流 SACK/NACK piggyback
- 既有 QP 的 EV 切换 (业务连续性)
- 完全不依赖 Clustermapper
- ms 级:Clustermapper 自探针
- link 级故障精确定位
- Gray failure 识别 (高丢包但未 down)
- 秒级:Policy controller
- 计算 denylist
- 下发到所有 node 的 MRC firmware
- 新建 QP 时 EV set 静态过滤掉坏 link 对应 EV
Denylist 价值
- link 级故障定位
- 提前过滤已知坏 link 的 EV
- 大面积故障的全局协调:一次性下发到所有 QP
验证数据
网络环境同上面的 “组网规格及物理实现”章节。实验数据要点如下
Point-to-point 基准(Cluster B)
使用 ib_write_lat 和 ib_write_bw 进行P2P测试,覆盖1个QP和4个QP的数据。但论文中没有说明 Latency 数据是否是P99还是average:

MRC vs RoCE+DCQCN(Cluster C)
在node的入向使用p4程序drop 固定百分比的报文,让其达到1%丢包和0.1%丢包,以来观察对吞吐的影响。
Cluster C 测试床
- 64 GPU (AMD MI355) + Pollara 400 Gb/s NIC
- BRCM TH5 交换机,2-tier Clos
配置对比
| 配置 | 拓扑 | PFC | CC | 路由 |
| RoCE | 单平面 400 Gb/s | 启用 | DCQCN | BGP+ECMP |
| MRC | 4 平面 × 100 Gb/s | 禁用 | ECN as LB signal | SRv6 静态路由 |
结论说明
这个测试数据比较有意思,可以得出如下结论,但要注意大厂一般都不会使用原生的DCQCN,而是会用自己的CC算法:
- MRC 1 QP > RoCE 16 QP,核心差异在 spraying 粒度(packet-level vs flow-level)
- 0.1% 丢包:MRC 几乎无感,RoCE 严重降级,真实 production cluster 偶尔会到这个水平
- 1% 丢包:MRC 还能跑 1/3 速,RoCE 不可用
- RoCE QP scaling 不能无限扩展,8 个 QP 后基本饱和。开 16 个 QP 没有比 8 个更好,有时甚至更差(QP 之间互相竞争 NIC 资源)
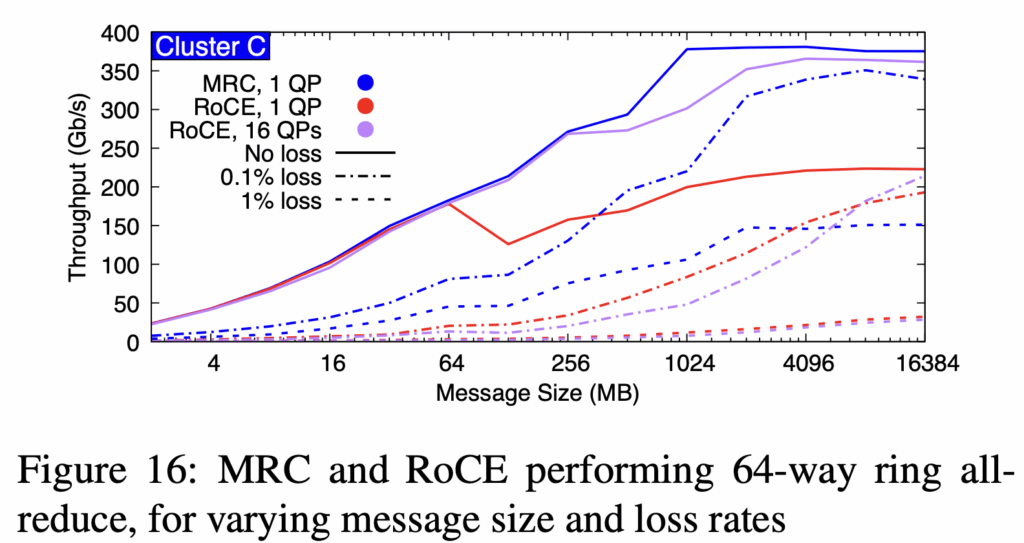
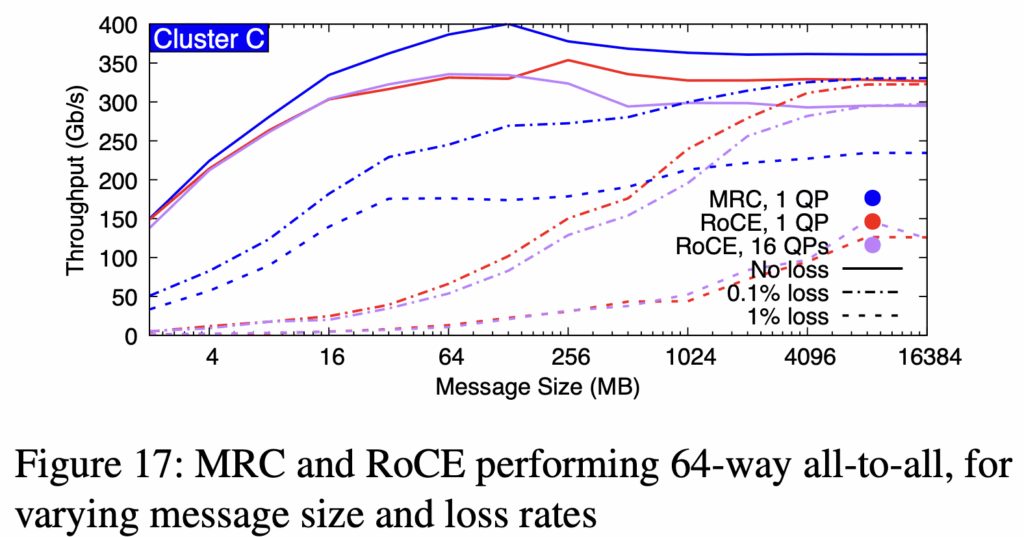
- All-to-all 天然比 Ring all-reduce 更耐丢包(多 QP 并发 mask,相当于如果只有1个QP,那个RTT时间就是都丢了,但多个QP,这个QP丢,但此时其他QP可能没丢。而这种mask对大消息作用明显,小消息RTT短,所以mask不明显,如下图),这对 MoE 模型设计有指导意义
Collateral damage(Cluster D)
Cluster D 测试床
- 16 server × 1 RTX6000 GPU + Broadcom Thor Ultra NIC
- BRCM TH5 用 VRF 模拟单平面 2-tier Clos(4 rack × 4 server + 4 spine)
- 400 Gb/s 全速(NIC-T0, T0-T1 都是 400 Gb/s)
- 关键:单平面,不是多平面,这是 MRC 唯一在单平面跑的实验
- Cross T1 incast 流量:7 sender → 1 receiver,victim 流跟receiver 在同一个T0,也在同一个队列
结论说明
- RoCE + DCQCN + 1QP:victim 流被 PFC 反扑到~300 Gb/s (-25%)
- RoCE + DCQCN + 8QP:多QP影响更严重,平均 ~300 Gb/s,但 1 秒级 dip 跌到 100 Gb/s (-75%)
- MRC:victim 流 100% 满速无影响,因为没有PFC,所以无头阻
- 如果只用PFC,那么影响会更大,可以参考图21.b,直接降到100g
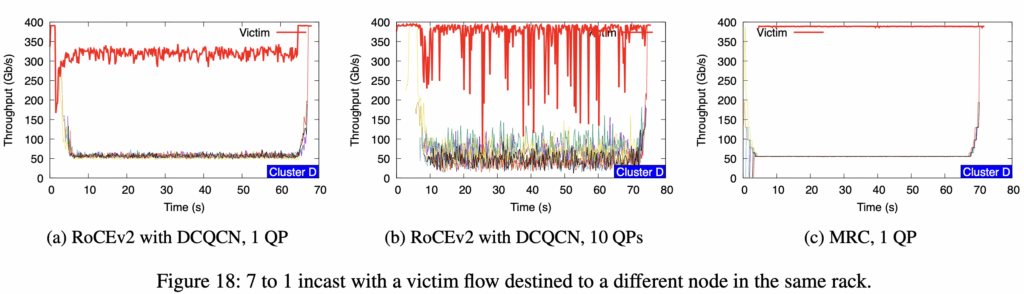
注:个人觉得这个图例有些问题,看最后victim恢复400g时,incast应该降为0,但它反而升到400g,无法解释为什么
DCQCN tuning 实验
这个实验的目的就是论证业界公认的:DCQCN不好调~ 对应的ECN也不好调~
实验场景:
- 15:1 incast:15 个 sender 打 1 个 receiver
- Flows arrive 5 seconds apart:每 5 秒加入 1 条新流(不是 15 条同时启动),5s 加第 1 条 → 10s 加第 2 条 → … → 75s 加完 15 条 → 之后保持 15:1 incast 状态
- 监控的是 leaf-host queue size(TOR 到目的 host 那条链路的出口队列长度)
- 测试了 3 套 DCQCN 参数
| 配置 | 队列控制 | PFC 触发 | Throughput 损失 |
| 22a Default | 流多了失控(涨到 20M+),< 10可以被控制 | 是(90s 后) | 0% (line-rate) |
| 22b More aggressive | 控住但抖到 0 | 否(推测) | ~10% |
| 22c Most aggressive | 控住,不触底 | 否(推测) | ~20% |
- 不够激进 → DCQCN 反应慢 → 队列堆满 → 触发 PFC → collateral damage
- 太激进 → DCQCN 过度抑制 sender → 队列偶尔空 → bottleneck link 没流量 → throughput loss
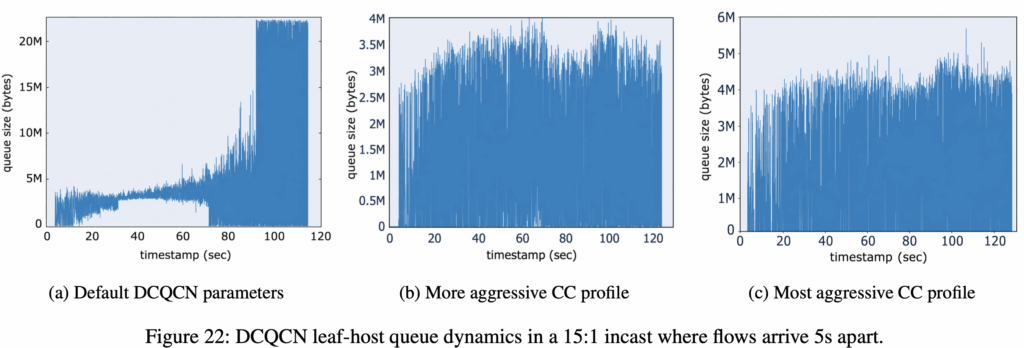
注:个人觉得这个图b和c应该标反了,越激进,buffer越少,空的越多,吞吐损失越多,这个更符合b,而不是c
版权声明:
本文链接:论文总结:Resilient AI Supercomputer Networking using MRC and SRv6
版权声明:本文为原创文章,仅代表个人观点,版权归 Frank Zhao 所有,转载时请注明本文出处及文章链接