论文总结:Alibaba HPN: A Data Center Network for Large Language Model Training
之前看完论文就完事了,过了一段时间后,很多细节就会忘记,需要重新看一遍……之前的兄弟习惯很好,看完会总结,忘记就看总结。所以趁着最近阿里发布的最新论文,我也总结下,为了以后复习用。
这篇论文写的很好,讲了很多阿里HPN的基础设施及架构细节,虽然不是全部,但也包含了大部分的内容,很难得。去堆叠部分我没写进去,这个在国内互联网已经很熟了,但目前看国外的互联网以及OCP上,还在讨论如何简化堆叠的双上联问题。论文也提到微软在2023年通过SmartNIC(w/ FPGA)来实现双活。
论文原文:
拓扑
DCN+拓扑
按照论文的说法,HPN是针对之前阿里DCN+架构进行优化演进而来的,DCN+是传统的3层CLOS架构(根据去年阿里发布灵骏的相关文章,架构应该不是这样的,应该更偏向HPN,架构从实践中演进~ ?):
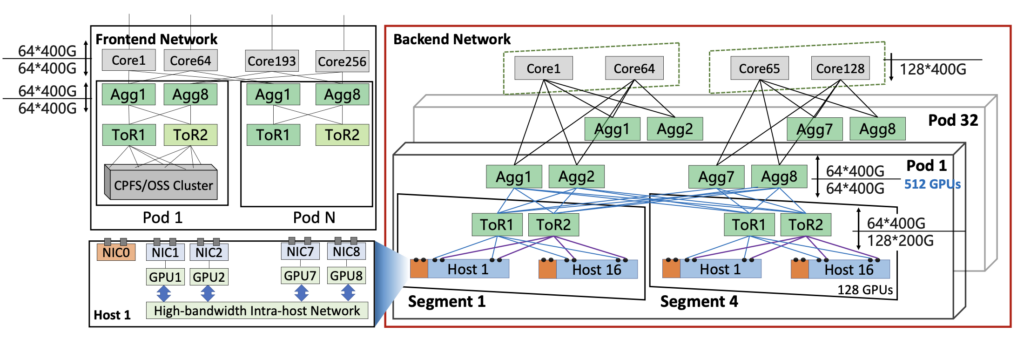
- Server:8 GPUs + 9 NICs,其中8个NIC对应8个GPU,1个NIC连Frontend Network,所有NIC都是2*200G,NIC型号应该是CX7;
- 每个Segment:包含128 GPUs/16台Server,16个200g/Server,所以共16*16=256个端口,正好是2台TOR的端口总量;
- 每个POD:8个AGG,1:1收敛比,TOR与AGG之间采用8 Links 互联,AGG1与每个Segment互联需要16 Links,因此共 16/4=4 个Segment;
- Core层:分2个平面,64台设备/平面,共128台设备。AGG1-4连平面1,因此Core可以连128/4=32个POD;AGG5-8连平面2,同上支持32个POD;
- GPU数量:128 GPUs * 4 Segments * 32 Pods = 16384;
HPN拓扑
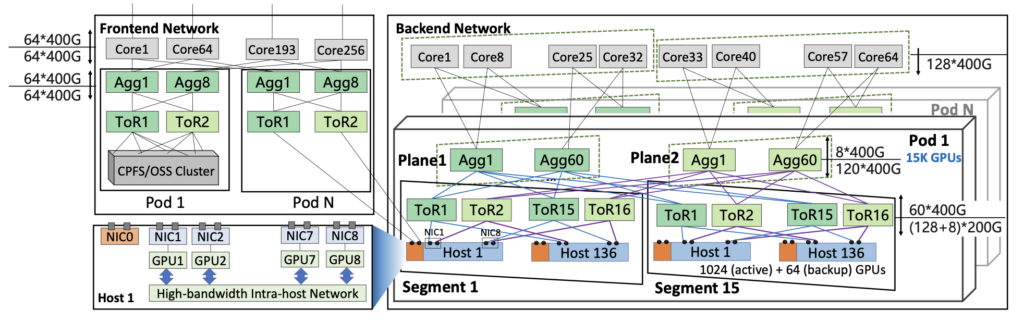
相对于DCN+,这次曝光的HPN架构还是有些新东西的,而且跟之前理解的有些不一样。
基础架构
- Server:同DCN+,只是NIC型号换成了BlueField3;
- 每个Segment:与DCN+不同,轨道优化架构(但不是我们理解的分轨,这里Server分轨连到了2个TOR上,这两个TOR分别全互联到了两个AGG平面上),16台 TOR / Segment,每个TOR连128+8=136台Server,收敛比是128:120 = 1.067:1,因此共支持128*8=1024 GPUs/Segment;
- 每个POD:与DCN+不同,分2个平面,每个平面60台 SW,分别覆盖去堆叠里的两台TOR。AGG的收敛比是8:120 = 1:15,共支持120/8 = 15 Segments,总共15*1024=15k GPUs/POD;
- Core层:采用双平面设计 + 基于源端口的Hash,64台设备总共64*128=8192端口。每个POD 120台SW,共120*8=960端口。因此总共8192/960 = 8 POD,120k GPUs;下面是Core与AGG互联的方式,由于1:15,所以上联端口只有8个,所以看上去是在一个平面里分成了4个小平面:
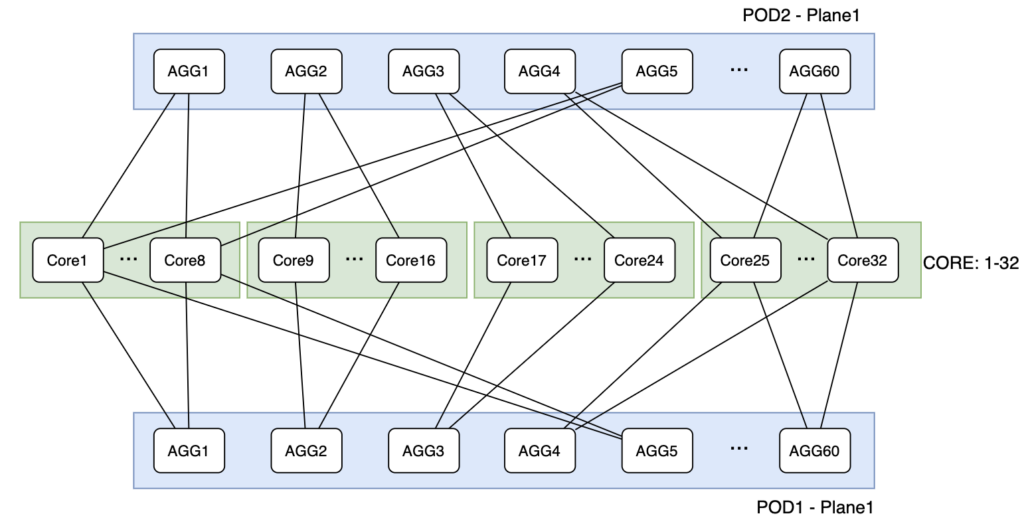
备份资源
TOR-AGG(Leaf)之间采用1.067:1的收敛比,TOR下行68*400G,其中4*400G用作备份,据说是模型开始训练前PP、TP、DP都提前规划好,同时为了故障时流量也不跨Segment,需要保障卡数不能减少,所以为了应对故障会多预留,那服务器、GPU卡都要做这么大的预留,感觉比较浪费。另外备份资源要如何替换任何轨道的故障GPU,不知道在业务上需要如何实现;
RePaC(Relative Path Control)
阿里认为交换机的解决方案 Flowlet和Per-packet spray都缺乏大规模部署的验证。对于端侧的解决方案,发现拥塞后做出的响应有可能加重拥塞。对于未来新的标准和协议,还有待验证。所以阿里选择使用类似腾讯的方案?使用交换机的HASH算法在控制器上拟合不想交的路径?但这个没有在论文中细讲,不过提到了RePac,看完这篇论文后再更新这部分信息吧。
另外由于分平面,这样找到不相交的路径变得相对容易,只需从上联的60个link中找即可。对比DGX SuperPOD,Jupiter和Fat tree,要更有优势:

去堆叠+双平面
去堆叠架构+AGG层双平面减少了HASH冲突(如下图远端TOR),但不能说消除了HASH冲突(TOR1到Plane1有多条链路,这里仍然会发生冲突,所以论文说的此架构消除了POD内的冲突6.1,不准确):
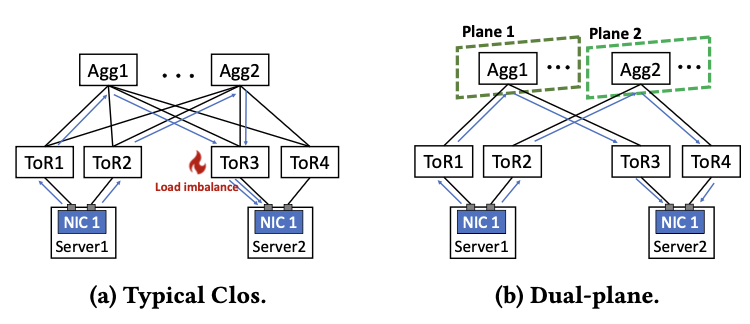
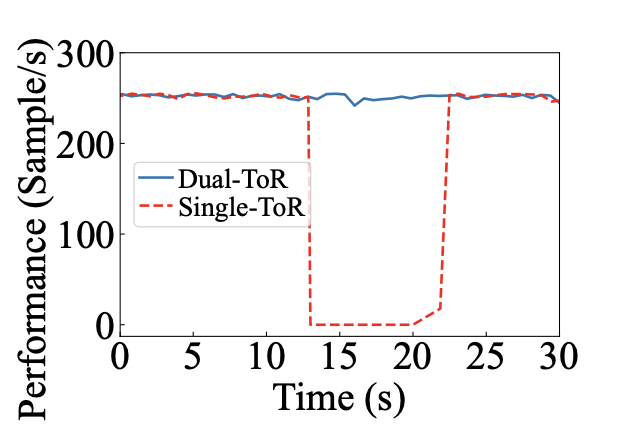
不过这里有个问题,在双平面下,如果Server1的NIC跟TOR1断了,Server2的NIC1要如何感知并做出反应?论文里我记得也提了,TOR跟Server之间不建议跑BGP,直接通过默认路由走网关的,所以这不就有黑洞了么?所以猜测应该是有其他方法来辅助操作(经过后面讨论,这个黑洞应该需要依赖第3层解决,这个第3层与POD应该是全互联,不过这跟论文里写的第三层分平面就有些对不上了),否则link flapping时应该会有黑洞产生丢包,而不是想下面那个数据那样,很平滑:
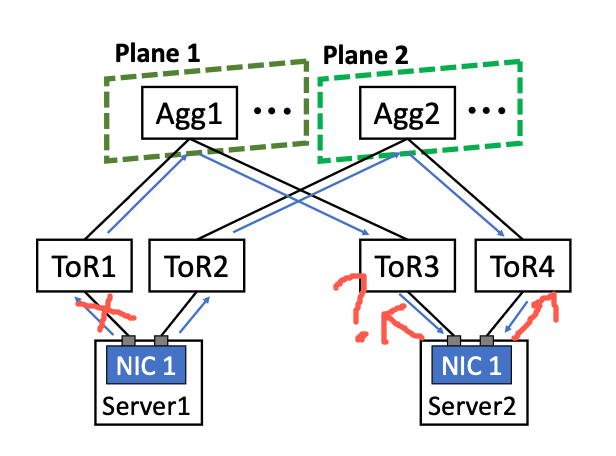
另外按论文里的说法,如果第2层采用完全的分轨方案,那么规模会更大,但这严重依赖机内跨轨。现有模型都是按分轨进行过优化的,所以没有问题。但对于新模型,或类似MOE这类All2All的模型,机内跨轨还是有局限,所以阿里在第2层单平面内采用了Fullmesh的方式,并结合第3层,来加大规模;
收敛比
在这个架构中,Server-TOR之间是有收敛比的(128:120 = 1.067:1,没包含4*400G的backup口),AGG-Core之间是有收敛比,1:15,POD访问需求少,并且可以在模型中进行设置,将最小的PP通信进行跨POD,大流量的DP、TP不做跨POD交互,第三层网络有收敛比应该是趋势、合理的,MATE的方案里面也有收敛比;

基于源端口Hash
之前业界在讨论基于源端口Hash时,主要的位置是在TOR层。包括BRCM的GLB,也有打算通过基于源端口Hash来扩充规模。目前阿里把这个带到了CORE层,尝试消除Hash冲突。并且明确了如果在基于源端口HASH的场景中,链路中断,那么受影响的流量需要回切到5元组HASH。
Frontend Network
前端网络主要用于管理和存储网络,采用1:1的收敛比,为了以后兼容推理网络。另外阿里认为现在的趋势是在推理场景中使用训练的GPU。因为有两个原因:
- 随着模型规模的增大,推理服务需要更高内存和性能的GPU,用于推理的GPU规格与用于训练的GPU规格越来越相似;
- 很多客户更喜欢在同一个租用的集群上部署训练和推理作业,以提高GPU的利用率(主要是成本问题吧);
存储网络放在Frontend network,主要是为了不影响训练的性能,另外就是客户使用的容器镜像和数据集通常存储在其他数据中心或客户自建集群中,这些外部数据无法通过Backend Network直接访问,因此这种网络设计要求流量在前后端之间通过代理,增加了软件开发的复杂性和相关的稳定性风险。所以Frontend Network应该包含类似网关的区域,负责代理和负载均衡东西向的流量,这样才能打通客户和推理的通道。
大模型相关
- 大模型中会定期发生流量突发,突发发生在每次训练迭代的后向阶段,其中所有数据并行(DP)组需要通过 AllReduce 集体通信操作来同步梯度;另外每个主机只有1k以内的连接:
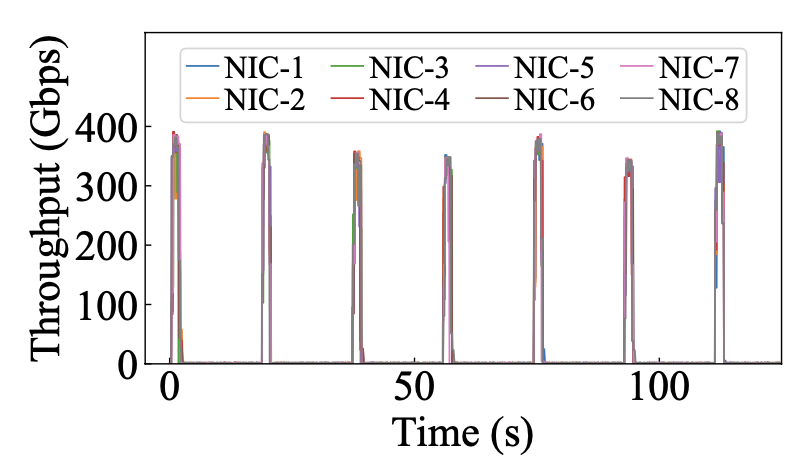
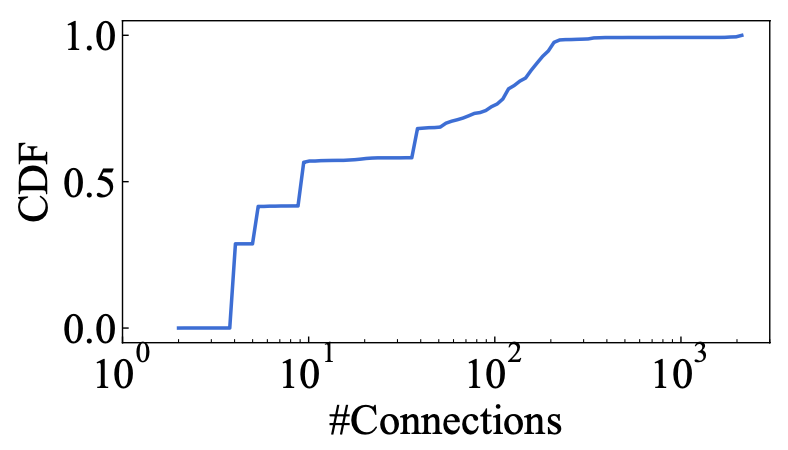
- 96.3%在线大模型训练任务所需的GPU少于1k卡,跨数万个 GPU 的单个训练作业不需要过多的 3 层网络资源;
- 为了应对训练中的故障,需要Checkpoint来保持当时的数据,这个需要大量存储空间(例如,每个 GPU 30GB)和高开销(例如 100s),一般客户几个小时(2-4h)做一次checkpoint;
- 对于定义一个训练集群,阿里(15k)同Google、AWS、Azure 和 NVIDIA的做法一致,规模一般都在 10K-30K GPU左右;
- 算法有容忍度,根据阿里的描述,故障超过2分钟没有回复,训练就无法恢复了;
其他
- 1个POD部署在单一的数据中心机房内,约定电力为18MW,可容纳约 15K GPU;
- 在机房内,所有光纤少于100m,并允许使用成本更低的多模光收发器(与单模光收发器相比,成本降低了 70%);
- 现有51.2T的硬件设计可以直接适配未来102.4T的芯片;
- 在去堆叠的架构中,为什么单通的问题不能依靠LACP来解决?什么bug导致最基本的方法失效?
- 如果使用纯轨道的方案,会获得更大规模,如Meta的rail-only topology,但需要依赖南向scale up网络提供更强的跨轨能力,以及模型适配;
版权声明:
本文链接:论文总结:Alibaba HPN: A Data Center Network for Large Language Model Training
版权声明:本文为原创文章,仅代表个人观点,版权归 Frank Zhao 所有,转载时请注明本文出处及文章链接