Mix for Fair-Queue and WRED on ASR1k’s class-default
最近接触了一个QOS的问题,借这个机会仔细研究了下对于Fair-Queue和WRED同时active时,QOS到底是如何working的。
当我们看到下面信息,能得出什么?OK, 咱们先不管是不是有burst,咱们先看看这些信息都代表什么。从qfp static drop中可以看到大部分都是TailDrop,那么这个TailDrop是谁执行的?那WRED又是在什么时候丢的包?数据包到底在default 队列遇到了什么导致了丢包?
Packets come in —> Per-flow queue —> WRED ?
#show platform hardware qfp active statistics drop ------------------------------------------------------------------------- Global Drop Stats Packets Octets ------------------------------------------------------------------------- TailDrop 3154567 2130943086 Wred 185939 121121238 class class-default fair-queue random-detect dscp-based bandwidth percent 5 Class-map: class-default (match-any) 55033554 packets, 26127126380 bytes 5 minute offered rate 212000 bps, drop rate 1000 bps Match: any Queueing queue limit 64 packets >>> 1. (queue depth/total drops/no-buffer drops/flowdrops) 0/263060/0/0 (pkts output/bytes output) 54769872/25950648448 Fair-queue: per-flow queue limit 16 packets >>> 2. Exp-weight-constant: 4 (1/16) >>> 3. Mean queue depth: 2 packets >>> 4. dscp Transmitted Random drop Tail/Flow drop Minimum Maximum Mark pkts/bytes pkts/bytes pkts/bytes thresh thresh prob default 51394130/25134195972 5139/3262566 6470/4132980 16 32 1/10 4 35175/5134718 0/0 1/146 16 32 1/10 cs1 775388/401417376 34/30220 48/46616 18 32 1/10 bandwidth 5% (204 kbps)
首先几个概念:
1. 64 packets 是默认的queue limited,也叫aggregate limit
2. 16 packets 是per-flow queue的大小,它默认是aggregate queue的25%,fair-queue有16个HW queue,每个queue都能装16 packets,所以一共是16*16=256
3. 用来计算平均队列的
4. 上一次计算得出的平均队列
下面是数据包进入后的过程:
1. per-flow hash (to get flow-id) ->
首先数据包进来后,会根据5元素 (src/dst ip, src/dst port, protocol) hash到这16个HW queue中的一个
2.per-flow qlimit tail-drop check ->
如果flow queue满了,那么flowdrop的计数会增加,这也会被记录到tail drop中,注意目前为止,这些drop只能通过下面的命令show出来,而且要反复show,这个drop计数10s会清一次: show platform hardware qfp active feature qos queue output interface GigabitEthernetx/x/x
至于为什么现有的flowdrops counter不增加,XE3.12就会支持flowdrops的计数了。
3. aggregate qlimit tail-drop check (only if WRED enabled) ->
从fair-queue出来,包会到虚拟Q,也就是aggregate queue,这个queue在这里是64 packets,如果数据包传送速度很快,导致这个queue也满了(64 packets),那么no-buffer的counter会增加。
在aggregate queue中实际的queue depth 叫瞬时queue depth(“instantaneous aggregate queue depth”),aggregate的tail drop不是根据配置的大小来决策的,而是根据平均queue depth(“average or mean aggregate queue depth”),默认的64 packets aggregate queue size只是其中一个因素。下面是具体算法:
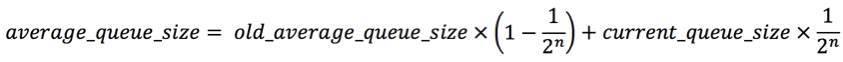
N就是上面看到的“Exp-weight-constant:4”
Current_queue_size 就是所谓的“instantaneous aggregate queue depth“
Old_average_queue_size 顾名思义就是上次得到的平均queue大小
4. aggregate qlimit WRED check (only if WRED enabled) ->
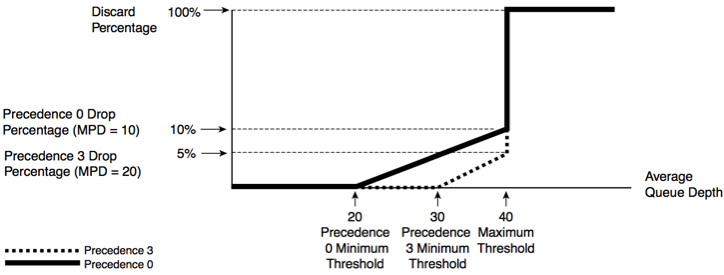
经过aggregate queue的缓冲,数据包终于来到最后的防线—WRED,还记得上面说的”mean aggregate queue depth“么,WRED就是是用这个来计算他自己的丢弃阀值,如下图所示:
下面是我根据自己的理解画的图,通过这张图,可以更好地了解这些顺序:
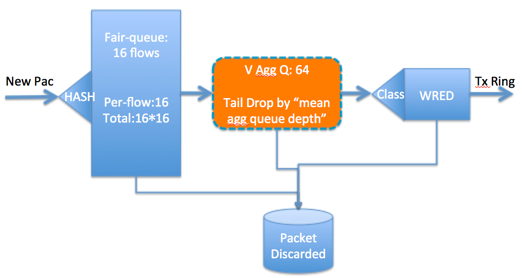
注意:在ASR1k上,如果同时使用了Fair-queue和WRED,要先配置WRED,然后再配置fair-queue,这是一个已知的limitation
版权声明:
本文链接:Mix for Fair-Queue and WRED on ASR1k’s class-default
版权声明:本文为原创文章,仅代表个人观点,版权归 Frank Zhao 所有,转载时请注明本文出处及文章链接