NCS6K: XRVM loses console
Problem
Customer get HostOS when connect to XRVM console after installing ISSU SMU, and confirmed XRVM normal work.
Background
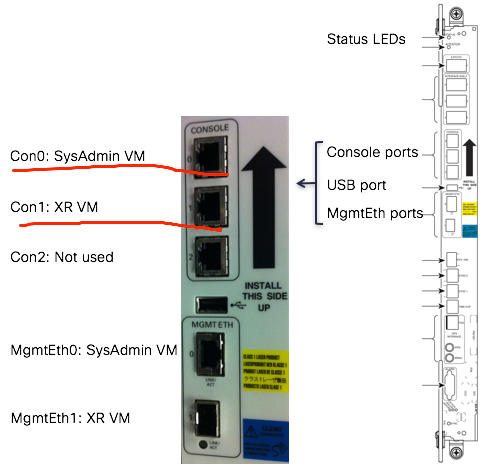
- SAVM and XRVM on all RPs and LCs, FC only have SAVM, check by “show vm” in admin vm, SAVM and XRVM mapping to console 0 & 1, as follow:
- Except SAVM and XRVM, have key components that is host system in RPs or LCs, you can check host by follow steps, login by “ssh ” after “chvrf 0 bash”.
sysadmin-vm:0_RP0# run Wed Nov 29 04:27:53.795 UTC [sysadmin-vm:0_RP0:~]$chvrf 0 bash [sysadmin-vm:0_RP0:~]$route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default 10.0.2.2 0.0.0.0 UG 0 0 0 eth0 10.0.2.0 * 255.255.255.0 U 0 0 0 eth0 192.0.0.0 * 255.0.0.0 U 0 0 0 eth-vf1.3073 RP/0/RP0/CPU0:6008-A#run Wed Nov 29 04:28:30.334 UTC [xr-vm_node0_RP0_CPU0:/]$chvrf 0 bash [xr-vm_node0_RP0_CPU0:/]$route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 172.0.0.0 * 255.0.0.0 U 0 0 0 eth-vf1.3074 192.0.0.0 * 255.0.0.0 U 0 0 0 eth-vf1.3073
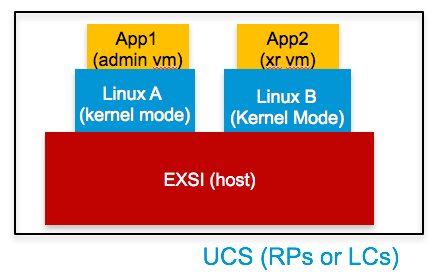
- How to understand SAVM, XRVM and host relaitonship? And what it is when you do “run” on admin VM or XR vum? As follow pic:
- Added kenerl info at SAVM/XRVM/Host, VM and host should have same kernel:
[host:~]$ cat /proc/version Linux version 3.10.19 (kmeng@sjc-ads-1005) (gcc version 4.4.1 (Wind River Linux Sourcery G++ 4.4a-341) ) #1 SMP Wed Jun 29 12:52:51 PDT 2016 [host:~]$ exit logout Connection to 10.0.2.2 closed. [sysadmin-vm:0_RP0:~]$cat /proc/version Linux version 3.10.19 (kmeng@sjc-ads-1005) (gcc version 4.4.1 (Wind River Linux Sourcery G++ 4.4a-341) ) #1 SMP Wed Jun 29 12:52:51 PDT 2016 [sysadmin-vm:0_RP0:~]$ [sysadmin-vm:0_RP0:~]$exit exit [sysadmin-vm:0_RP0:~]$exit exit sysadmin-vm:0_RP0# exit Thu Nov 30 22:01:56.808 UTC RP/0/RP0/CPU0:6008-A#run Thu Nov 30 22:01:56.607 UTC [xr-vm_node0_RP0_CPU0:/]$cat /proc/version Linux version 3.10.19 (kmeng@sjc-ads-1005) (gcc version 4.4.1 (Wind River Linux Sourcery G++ 4.4a-341) ) #1 SMP Wed Jun 29 12:52:51 PDT 2016
Troubleshooting
VM Manager will check platform value in /proc/cmdline file before allocate console to XRVM. On the problematic node, the platform is set to a wrong value:
[sysadmin-vm:0_RP0:~]$cat /proc/cmdline root=LABEL=Calvados platform=root=/dev/vda1 boardtype=RP vmtype=sysadmin-vm console=tty0 console=hvc0 prod=1 crashkernel=0 bigphysarea=100M quiet cgroup_disable=memory pci=hpmemsize=0M,hpiosize=0M
On the normal node, the platform should be set to “panini”
[sysadmin-vm:0_RP0:~]$ cat /proc/cmdline root=LABEL=Calvados platform=panini boardtype=RP vmtype=sysadmin-vm console=tty0 console=hvc0 prod=1 crashkernel=0 bigphysarea=100M quiet cgroup_disable=memory pci=hpmemsize=0M,hpiosize=0M
The platform value is copied from /boot/grub/menu.lst file, we see it’s wrong in both SAVM and XRVM
admin vm:
sysadmin-vm:0_RP0# run chvrf 0 more /boot/grub/menu.lst
Tue Nov 7 13:25:14.137 UTC
default 0
timeout 0
title XR-TEST
root (hd0,0)
kernel /boot/bzImage root=LABEL=Calvados platform=root=/dev/vda1 boardtype=RP vmtype=sysadmin-vm console=tty0 console=hvc0 prod=1 crashkernel=0 bigphysarea=100M quiet cgroup_disable=memory pci=hpmemsize=0M,hpiosize=0M
initrd /boot/initrd.img
xrvm
[xr-vm_node0_RP0_CPU0:~]$more /boot/grub/menu.lst
default 0
timeout 0
title XR-TEST
root (hd0,0)
kernel /boot/bzImage root=LABEL=XR platform=root=/dev/vda1 boardtype=RP vmtype=xr-vm console=tty0 console=hvc0 prod=1 crashkernel=0 bigphysarea=200M quiet cgroup_disable=memory pci=hpmemsize=0M,hpiosize=0M
initrd /boot/initrd.img
Why the issue was triggered by ISSU
Normal reload should not check the menu lst so no issue happens even if menu lst incorrect, only when vmid change from default 1, that will trigger check menu lst, so have this issue. So the wrong platform type and XR ISSU SMU, when VM ID changes from 1 to 2, create the conditions for console to fail.
Refer to vmid that can check by “show vm location x/x” in admin vm.
VMID change after do ISSU, as follow alarm:
![]()
In general, there might be other implications of having the wrong platform type, so console lost only one symptom.
How to workaround
There are two options, you can choose one:
- you can correct the menu.lst for two RP at admin vm, then reload chassis.
- you can correct the menu.lst for two RP at admin vm, switchover to recovery, as follow detail steps:
– login to ncs6k by ssh
– login to admin mode by “admin”
– login to active admin vm kernel by “run”
– vim menu.lst at active admin vm by “vim /boot/grub/menu.lst”
– correct platform part from “platform=root=/dev/vda1” to “platform=panini”
– exit and back to admin mode, then check standby admin vm address by “show vm”
– login to standby admin vm kernel by “run chvrf 0 ssh x.x.x.x”
– please do same action same as 4-5.
– after correct active/standby admin vm menu.lst, reload standby rp by “hw-module location 0/rpx reload” in admin vm.
– now standby rp should recovery, you can check standby console status
– then reload the active rp by “hw-module location 0/rpx reload” in admin vm, that will auto switchover to standby rp, and – console of active rp will recovery.