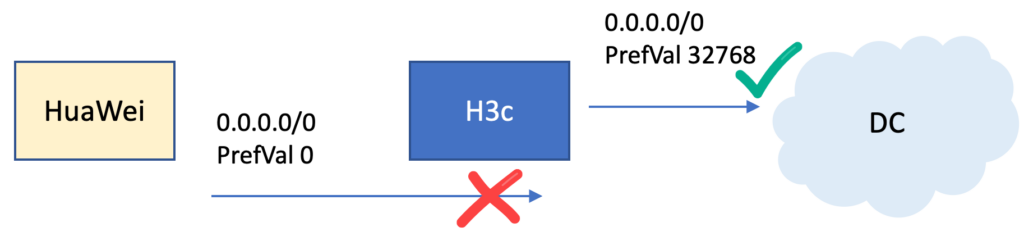
If the routes have the same weight, use the route with the highest local preference. The local preference attribute only is local to the autonomous system and does not get passed to EBGP neighbors. The higher the local preference, the more preferred the route is. 默认情况下,从EBGP学来的路由local preference是100,解决本AS域出口路由选择。他不会把此参数传递给EBGP的邻居,优选值高的;
Originated
If the routes have the same local preference, prefer the route that was originated by BGP on this router. 优选从本路由器使发的路由,包括本地network,重分发和或IGP已有的路由,有BGP配置的聚合地址也包括在内。查看BGP路由表时可以看到有时路由前面带了一个“r”,说明在IGP中已经存在此路由了;
router ospf 1
router-id 10.1.6.6
log-adjacency-changes
network 10.1.6.6 0.0.0.0 area 0
network 10.1.46.0 0.0.0.255 area 1
!
CE2#sh ip route
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 3 subnets
C 10.1.6.0 is directly connected, Loopback0
C 10.1.46.0 is directly connected, Ethernet0/0
O E2 10.1.38.0 [110/1] via 10.1.46.4, 02:11:33, Ethernet0/0
Rack1R3(config)#ip prefix-list per7 permit 10.1.7.0/24
Rack1R3(config)#route-map per7
Rack1R3(config-route-map)#match ip add prefix-list per7
Rack1R3(config-route-map)#set extcommunity rt 1:68
Rack1R3(config-route-map)#set extcommunity rt 1:68 ?
ASN:nn or IP-address:nn VPN extended community
additive Add to the existing extcommunity
<cr>
Rack1R3(config-route-map)#set extcommunity rt 1:68 add
Rack1R3(config-route-map)#end
Rack1R3#
Rack1R3(config)#ip vrf r5-sw1
Rack1R3(config-vrf)#export map per7
Rack1R3(config-vrf)#end
Rack1R3#clear ip bgp * sof
Rack1R4#sh ip bgp vpn all
BGP table version is 30, local router ID is 10.1.4.4
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 1:57 (default for vrf r5-sw1)
*>i10.1.7.0/24 150.1.3.3 0 100 0 ?
Route Distinguisher: 1:68 (default for vrf r6-sw2)
*> 10.1.6.6/32 10.1.46.6 0 32768 ?
*>i10.1.7.0/24 150.1.3.3 0 100 0 ?
Rack1R4#
Rack1R4#
Rack1R4#sh ip bgp vpn all 10.1.7.0
BGP routing table entry for 1:57:10.1.7.0/24, version 26
Paths: (1 available, best #1, table r5-sw1)
Not advertised to any peer
Local
150.1.3.3 (metric 130) from 150.1.3.3 (150.1.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal, best
Extended Community: RT:1:57 RT:1:68,
mpls labels in/out nolabel/25
BGP routing table entry for 1:68:10.1.7.0/24, version 27
Paths: (1 available, best #1, table r6-sw2)
Not advertised to any peer
Local, imported path from 1:57:10.1.7.0/24
150.1.3.3 (metric 130) from 150.1.3.3 (150.1.3.3)
Origin incomplete, metric 0, localpref 100, valid, internal, best
Extended Community: RT:1:57 RT:1:68,
mpls labels in/out nolabel/25