K8s – CNI Network Component
我看的教程算是2020年初的,所以根据现在的时间,已经过去两年半了,下面的信息不一定很准确,后面如果哪里不正确,随着学习的深入,再更改和说明。CNI的全程是Container Network Interface,主要为了解决Pod资源在不同宿主机之间互通的。
常见CNI组件
所有CNI都部署在node节点;
- Flannel,19年的市场占有率38%;
- Calico,19年的市场占有率35%;
- Canal:结合了flannel和calico;19年的市场占有率5%;
- Contiv:思科开源的;
- OpenContrail:Juniper开源的;
- NSX-T:vmware开源的;
- Kube-router:试图取代kube-proxy,但使用的不多;
Flannel
安装部署Flannel
可以从Github上直接下载,目前Link在这里:https://github.com/flannel-io/flannel/releases/download/v0.11.0/flannel-v0.11.0-linux-amd64.tar.gz,但国内环境可能不好,所以需要科学上网或者多尝试几次;分别在node13和node14上部署Flannel:
root@f0-13:/opt/src# mkdir /opt/flannel-v0.11.0
root@f0-13:/opt/src# tar xf flannel-v0.11.0-linux-amd64.tar.gz -C /opt/flannel-v0.11.0/
root@f0-13:/opt/src# ln -s /opt/flannel-v0.11.0/ /opt/flannel
root@f0-13:/opt/src# cd /opt/flannel
root@f0-13:/opt/flannel# ll
total 34444
drwxr-xr-x 2 root root 4096 Aug 13 11:46 ./
drwxr-xr-x 7 root root 4096 Aug 13 11:48 ../
-rw-r--r-- 1 root root 4300 Oct 23 2018 README.md
-rwxr-xr-x 1 root root 35249016 Jan 29 2019 flanneld*
-rwxr-xr-x 1 root root 2139 Oct 23 2018 mk-docker-opts.sh*root@f0-13:/opt/flannel# mkdir certs
root@f0-13:/opt/flannel# cd certs/
root@f0-13:/opt/flannel/certs# cp /opt/kubernetes/server/bin/certs/client* ./
root@f0-13:/opt/flannel/certs# cp /opt/kubernetes/server/bin/certs/ca.pem ./
root@f0-13:/opt/flannel/certs# ll
total 20
drwxr-xr-x 2 root root 4096 Aug 13 11:50 ./
drwxr-xr-x 3 root root 4096 Aug 13 11:50 ../
-rw-r--r-- 1 root root 1127 Aug 13 11:50 ca.pem
-rw------- 1 root root 1679 Aug 13 11:50 client-key.pem
-rw-r--r-- 1 root root 1261 Aug 13 11:50 client.pem注意FLANNEL_NETWORK设置的是所有pod的网段,换句话说就是docker的网段,在我这里就是172.1.0.0/16,因为node13用的是172.1.13.x/24,而node14用的是172.1.14.x/24,而FLANNEL_SUBNET则是本机docker的子网:
root@f0-13:/opt/flannel# more subnet.env
FLANNEL_NETWORK=172.1.0.0/16
FLANNEL_SUBNET=172.1.13.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
root@f0-13:/opt/flannel#
root@f0-13:/opt/flannel# chmod +x flanneld.sh
root@f0-13:/opt/flannel# more flanneld.sh
#!/bin/sh
./flanneld \
--public-ip=172.20.0.13 \
--etcd-endpoints=https://172.20.0.12:2379,https://172.20.0.13:2379,https://172.20.0.14:2379 \
--etcd-keyfile=./certs/client-key.pem \
--etcd-certfile=./certs/client.pem \
--etcd-cafile=./certs/ca.pem \
--iface=ens3 \
--subnet-file=./subnet.env \
--healthz-port=2401 root@f0-13:/opt/flannel# mkdir -p /data/logs/flanneld
root@f0-13:/opt/flannel# more /etc/supervisor/conf.d/flannel.conf
[program:flanneld-0-13]
command=/opt/flannel/flanneld.sh ; the program (relative uses PATH, can take args)
numprocs=1 ; number of processes copies to start (def 1)
directory=/opt/flannel ; directory to cwd to before exec (def no cwd)
autostart=true ; start at supervisord start (default: true)
autorestart=true ; retstart at unexpected quit (default: true)
startsecs=30 ; number of secs prog must stay running (def. 1)
startretries=3 ; max # of serial start failures (default 3)
exitcodes=0,2 ; 'expected' exit codes for process (default 0,2)
stopsignal=QUIT ; signal used to kill process (default TERM)
stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10)
user=root ; setuid to this UNIX account to run the program
redirect_stderr=true ; redirect proc stderr to stdout (default false)
stdout_logfile=/data/logs/flanneld/flanneld.stdout.log ; stderr log path, NONE for none; default AUTO
stdout_logfile_maxbytes=64MB ; max # logfile bytes b4 rotation (default 50MB)
stdout_logfile_backups=4 ; # of stdout logfile backups (default 10)
stdout_capture_maxbytes=1MB ; number of bytes in 'capturemode' (default 0)
stdout_events_enabled=false ; emit events on stdout writes (default false)设置etcd
增加host-gw模型,flannel还支持vxlan模型;如果下面的地址填错了,可以用“./etcdctl rm /coreos.com/network/config”删除,然后重新set:
root@f0-13:/opt/etcd# ./etcdctl set /coreos.com/network/config '{"Network": "172.1.0.0/16", "Backend": {"Type": "host-gw"}}'
{"Network": "172.1.0.0/16", "Backend": {"Type": "host-gw"}}
root@f0-13:/opt/etcd# ./etcdctl get /coreos.com/network/config
{"Network": "172.1.0.0/16", "Backend": {"Type": "host-gw"}}验证和总结
root@f0-13:/opt/flannel# supervisorctl update
flanneld-0-13: added process group
root@f0-13:/opt/flannel# supervisorctl status
etcd-server-0-13 RUNNING pid 754, uptime 2 days, 5:02:40
flanneld-0-13 RUNNING pid 1139448, uptime 0:00:43
kube-apiserver-0-13 RUNNING pid 755, uptime 2 days, 5:02:40
kube-controller-manager-0-13 RUNNING pid 840066, uptime 16:09:08
kube-kubelet-0-13 RUNNING pid 759, uptime 2 days, 5:02:40
kube-proxy-0-13 RUNNING pid 761, uptime 2 days, 5:02:40
kube-scheduler-0-13 RUNNING pid 840058, uptime 16:09:08subnet.env中的网络配置开始设置错了,导致node13的flannel总是使用一个奇怪的地址,经过查看flannel的启动日志,发现复用了老的IP,而没使用更正后的subnet.env,估计是因为当时网络有问题导致自动分了一个地址,这个地址被写入了etcd。但这要如何修复呢?我尝试重启,重新配置subnet.env均不生效,都被老IP替换了,经过查找,需要把etcd的信息改掉或删掉才可以,我直接删掉了,然后重启flannel恢复正常:
root@f0-13:/opt/flannel# more subnet.env
FLANNEL_NETWORK=172.1.0.0/16
FLANNEL_SUBNET=172.1.36.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=falseroot@f0-13:/opt/flannel# more /data/logs/flanneld/flanneld.stdout.log |grep 172.1.36.0 -C 5
2022-08-13 16:13:28.582351 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
I0813 16:13:28.584654 763 main.go:244] Created subnet manager: Etcd Local Manager with Previous Subnet: 172.1.13.0/24
I0813 16:13:28.584670 763 main.go:247] Installing signal handlers
I0813 16:13:28.589980 763 main.go:587] Start healthz server on 0.0.0.0:2401
I0813 16:13:30.265734 763 main.go:386] Found network config - Backend type: host-gw
I0813 16:13:30.290094 763 local_manager.go:147] Found lease (172.1.36.0/24) for current IP (172.20.0.13), reusing
I0813 16:13:30.297810 763 main.go:317] Wrote subnet file to ./subnet.env
I0813 16:13:30.298041 763 main.go:321] Running backend.
I0813 16:13:30.298437 763 route_network.go:53] Watching for new subnet leases
I0813 16:13:30.311451 763 main.go:429] Waiting for 22h59m59.323986135s to renew lease
I0813 16:13:30.318417 763 route_network.go:85] Subnet added: 172.1.14.0/24 via 172.20.0.14root@f0-13:/opt/etcd# ./etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/172.1.14.0-24
/coreos.com/network/subnets/172.1.36.0-24root@f0-13:/opt/etcd# ./etcdctl --cert-file=./certs/etcd-peer.pem --key-file=./certs/etcd-peer-key.pem --ca-file=./certs/ca.pem rmdir /coreos.com/network/subnets/172.1.36.0-24
2022-08-13 17:09:41.747978 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
PrevNode.Value: {"PublicIP":"172.20.0.13","BackendType":"host-gw"}root@f0-13:/opt/etcd# ./etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/172.1.14.0-24root@f0-13:/opt/flannel# supervisorctl start flanneld-0-13
flanneld-0-13: started
root@f0-13:/opt/flannel# cd ../etcd
root@f0-13:/opt/etcd# ./etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/172.1.14.0-24
/coreos.com/network/subnets/172.1.13.0-24修复上面的问题后,再查看路由表,可以看到flannel已经在宿主机上创建了一条正确的静态路由,这样不同宿主机的pods就可以互通了,所以flannel的host-gw模式其实就是添加了一个静态路由而已,没有任何其他东西。另外注意:host-gw模式只能在l2网络中使用,也就是不同宿主机在同网段,如果宿主机在不同网段,那么就需要vxlan模式了:
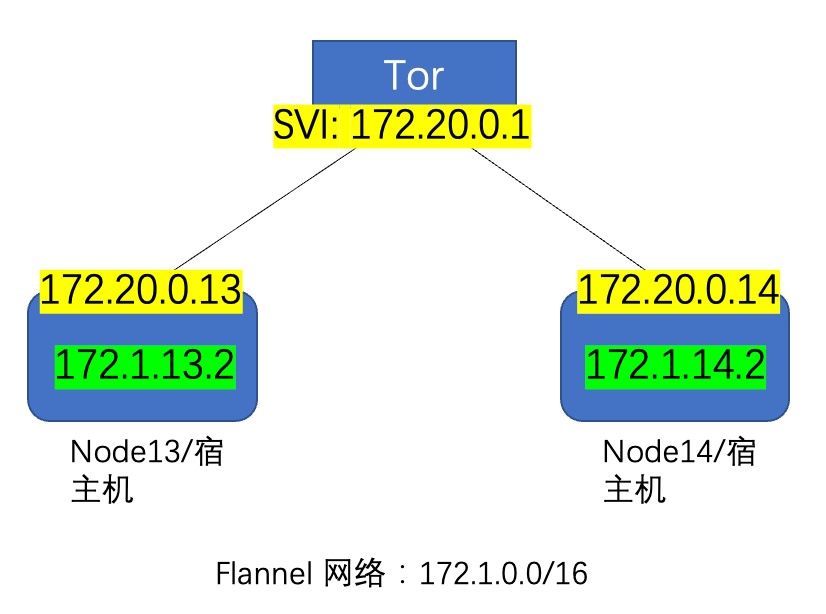
root@f0-13:~# ip route
default via 172.20.0.1 dev ens3 proto static
172.1.13.0/24 dev docker0 proto kernel scope link src 172.1.13.1
172.1.14.0/24 via 172.20.0.14 dev ens3
172.20.0.0/24 dev ens3 proto kernel scope link src 172.20.0.13
root@f0-13:~#
root@f0-13:~#
root@f0-13:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ds-2jnw2 1/1 Running 1 2d6h 172.1.13.2 f0-13.host.com <none> <none>
nginx-ds-6n9d8 1/1 Running 1 2d6h 172.1.14.2 f0-14.host.com <none> <none>
root@f0-13:~#
root@f0-13:~# ping 172.1.14.2
PING 172.1.14.2 (172.1.14.2) 56(84) bytes of data.
64 bytes from 172.1.14.2: icmp_seq=1 ttl=63 time=1.53 ms
64 bytes from 172.1.14.2: icmp_seq=2 ttl=63 time=0.247 ms
64 bytes from 172.1.14.2: icmp_seq=3 ttl=63 time=0.298 ms
^C
--- 172.1.14.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2020ms
rtt min/avg/max/mdev = 0.247/0.692/1.533/0.594 msFlannel之SNAT规则优化
开启flannel后,两个pod 互相访问时,使用的地址是真实的pod地址么?从结果上看应该是呀,但其实之间经过了NAT,这是因为pod如果访问外网,可以用宿主机的IP进行交换,否则直接用pod的ip访问,报文是回不来的。但问题是如果只是在网内互访,需要NAT么?显然是不需要的,那么如何对其进行优化,使其满足不同场景?
如下实验可以容易的展示报文是经过NAT的,从f0-13的pod上ping f0-14的pod,然后再f0-14上抓包,看下交互报文:
root@f0-13:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ds-5cbw4 1/1 Running 0 42s 172.1.13.2 f0-13.host.com <none> <none>
nginx-ds-pgn66 1/1 Running 0 33s 172.1.14.2 f0-14.host.com <none> <none>root@f0-13:~# kubectl exec -ti nginx-ds-5cbw4 /bin/bash
root@nginx-ds-5cbw4:/# ping 172.1.14.2
PING 172.1.14.2 (172.1.14.2): 56 data bytes
64 bytes from 172.1.14.2: icmp_seq=0 ttl=62 time=2.902 ms
64 bytes from 172.1.14.2: icmp_seq=1 ttl=62 time=0.458 ms
64 bytes from 172.1.14.2: icmp_seq=2 ttl=62 time=0.388 ms
64 bytes from 172.1.14.2: icmp_seq=3 ttl=62 time=1.225 ms
^C--- 172.1.14.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.388/1.243/2.902/1.012 msroot@f0-14:~# tcpdump -i ens3 -p icmp -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens3, link-type EN10MB (Ethernet), capture size 262144 bytes
19:56:37.308964 IP 172.20.0.13 > 172.1.14.2: ICMP echo request, id 27, seq 0, length 64
19:56:37.310211 IP 172.1.14.2 > 172.20.0.13: ICMP echo reply, id 27, seq 0, length 64
19:56:38.308984 IP 172.20.0.13 > 172.1.14.2: ICMP echo request, id 27, seq 1, length 64
19:56:38.309063 IP 172.1.14.2 > 172.20.0.13: ICMP echo reply, id 27, seq 1, length 64
19:56:39.310095 IP 172.20.0.13 > 172.1.14.2: ICMP echo request, id 27, seq 2, length 64
19:56:39.310171 IP 172.1.14.2 > 172.20.0.13: ICMP echo reply, id 27, seq 2, length 64
19:56:40.311248 IP 172.20.0.13 > 172.1.14.2: ICMP echo request, id 27, seq 3, length 64
19:56:40.312139 IP 172.1.14.2 > 172.20.0.13: ICMP echo reply, id 27, seq 3, length 64
^C
8 packets captured
8 packets received by filter
0 packets dropped by kernel转换会发生在postrouting中,通过iptables可以查看这部分信息,从中可以找到如下信息:原地址为172.1.13.0/24,出接口docker0,那么转换原地址。也就是这个规则覆盖的场景是两个pod在同一个宿主机下的互访情况,但并不包含不同宿主机之间访问的场景:
root@f0-13:~# iptables-save|grep -i postrouting
:POSTROUTING ACCEPT [68:4135]
:KUBE-POSTROUTING - [0:0]
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -s 172.1.13.0/24 ! -o docker0 -j MASQUERADE
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
root@f0-13:~# 因此我们需要优化这个SNAT表项,让其覆盖这两种场景。为了更改iptables,需要特定工具重启后可以自动加载修改后的配置,可以安装”iptables-persistent“,可以参考这里:
root@f0-13:~# apt-get install iptables-persistent -y
root@f0-13:~# ll /etc/iptables/
total 16
drwxr-xr-x 2 root root 4096 Aug 13 21:16 ./
drwxr-xr-x 101 root root 4096 Aug 13 21:16 ../
-rw-r--r-- 1 root root 3240 Aug 13 21:16 rules.v4
-rw-r--r-- 1 root root 183 Aug 13 21:16 rules.v6优化表项并保持,重启后仍然生效:
root@f0-13:~# iptables -t nat -D POSTROUTING -s 172.1.13.0/24 ! -o docker0 -j MASQUERADE
root@f0-13:~# iptables -t nat -I POSTROUTING -s 172.1.13.0/24 ! -d 172.1.0.0/16 ! -o docker0 -j MASQUERADE
root@f0-13:~# iptables-save > /etc/iptables/rules.v4
root@f0-13:~# iptables-save > /etc/iptables/rules.v6
root@f0-13:~# more /etc/iptables/rules.v4 |grep POSTROUTING
:POSTROUTING ACCEPT [2:120]
:KUBE-POSTROUTING - [0:0]
-A POSTROUTING -s 172.1.13.0/24 ! -d 172.1.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE再次测试下,根据下面输出信息,已经显示真实pod的ip了(ps:我重建了pod1,所以pod的ip和name都换了):
root@f0-13:~# kubectl exec -ti nginx-ds-2q9mj /bin/bash
root@nginx-ds-2q9mj:/# ping 172.1.14.2 -c 2 ]
PING 172.1.14.2 (172.1.14.2): 56 data bytes
64 bytes from 172.1.14.2: icmp_seq=0 ttl=62 time=2.360 ms
64 bytes from 172.1.14.2: icmp_seq=1 ttl=62 time=0.379 ms
--- 172.1.14.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.379/1.369/2.360/0.991 msroot@f0-14:~# tcpdump -i ens3 -p icmp -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens3, link-type EN10MB (Ethernet), capture size 262144 bytes
21:31:56.147423 IP 172.1.13.3 > 172.1.14.2: ICMP echo request, id 14, seq 0, length 64
21:31:56.148939 IP 172.1.14.2 > 172.1.13.3: ICMP echo reply, id 14, seq 0, length 64
21:31:57.148030 IP 172.1.13.3 > 172.1.14.2: ICMP echo request, id 14, seq 1, length 64
21:31:57.148103 IP 172.1.14.2 > 172.1.13.3: ICMP echo reply, id 14, seq 1, length 64
^C
4 packets captured
6 packets received by filter
0 packets dropped by kernel