“在100Gbps网络中TCP单流能跑到多少?”引起的讨论
这两天看到一篇华为的《智能无损网络技术白皮书》,里面有这么一句,如下:

由于不知道得出这些数据是在什么场景下,所以先不管这些数据是否精准。主要比较好奇TCP单流为什么上不去?瓶颈在哪里?是否可以通过优化来提升性能?根据这些问题进行了一系列的学习和讨论,这篇文章主要记录现阶段的一些结论汇总,并梳理了之前常用技术的前世今生,打通了整个脉络。在此也感谢服务器大佬的指点。本文只讨论Linux服务器的性能,不包含网络产生的瓶颈,内容随时更正并补充。
如何体现TCP性能
TCP传输数据主要先握手,再发送数据。为了提高效率,在握手阶段会协商Windows Size,来确定传送报文的大小,然后根据接口MTU确认MSS大小,并把整个报文根据MSS分成不同的Segment,通过七层协议封包后发出去。其中报文大小(或者说Windows Size)就是TCP性能的重要体现,那么链路的带宽和Windows Size之间是什么关系,如何计算?其实我们可以很容易得出这个公式:
Maximum Throughput [bytes] = TCP Receive Window Size [bytes] / RTT [seconds]
TCP Receive Window Size [bytes] = Maximum Throughput [bytes] * RTT [seconds]我们可以简单计算下理想状态下100Gbps的网络,TCP的Windows Size需要设置多少可以跑满带宽。不过在这之前还需要考虑RTT往返时延,这个可以根据下面参数大体计算得出(来自其他计算PFC时延资料):
- MAC 封包时延:80ns
- MAC 解包时延:120ns
- 链路距离(光纤):5ns/米
- 链路时延:MTU / 链路带宽 = 9KB*8 / 100Gbps = 0.00000072 =720ns
所以在距离100米100g互联的RTT = 2 * ( 80 + 120 + 500 + 720 ) = 2840ns = 0.000003s;因此根据上面公式可以得出:
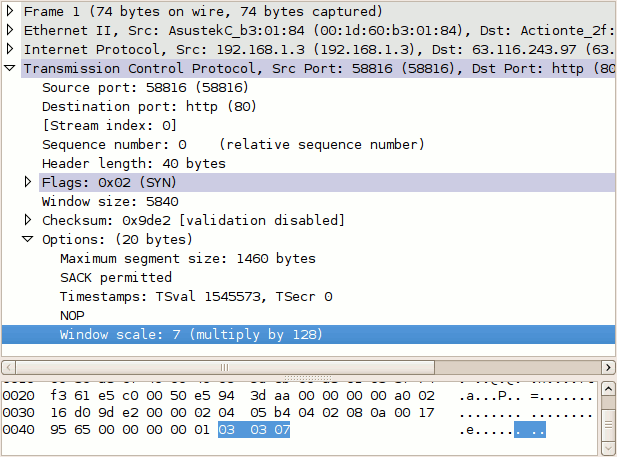
TCP Receive Window Size [bytes] = 100Gbps/8 * 0.000003s = 0.0375 MByte = 38 kByte如果延迟增加,Windows Size将会增加,默认16bit(65535),为了扩充未来场景,在RFC 1323规定了Window Scaling(扩充到32bit),来支持更大的Windows Size,比如下面图片来自https://packetlife.net/blog/2010/aug/4/tcp-windows-and-window-scaling,Windows Size = 5840 * 128 = 747520Byte :
单TCP流吞吐上不去的原因?
接上一小节,在Windows Size满足跑满整个带宽的大小后,是不是就意味着单TCP流可以跑满100g?答案是不行的,关于性能限制还是有很多的,有篇不错的实验论文(此论文没有解释为什么单TCP流无法跑满100g,但做了几种测试来验证不同场景下性能的变化)值得一看:https://doc.tm.kit.edu/2019-LCN-100g-tuning-authors-copy.pdf,另一篇更有名的是SIGCOMM ’21的:Understanding host network stack overheads。用下面这张图可以比较好的描述TCP交互的大致过程:
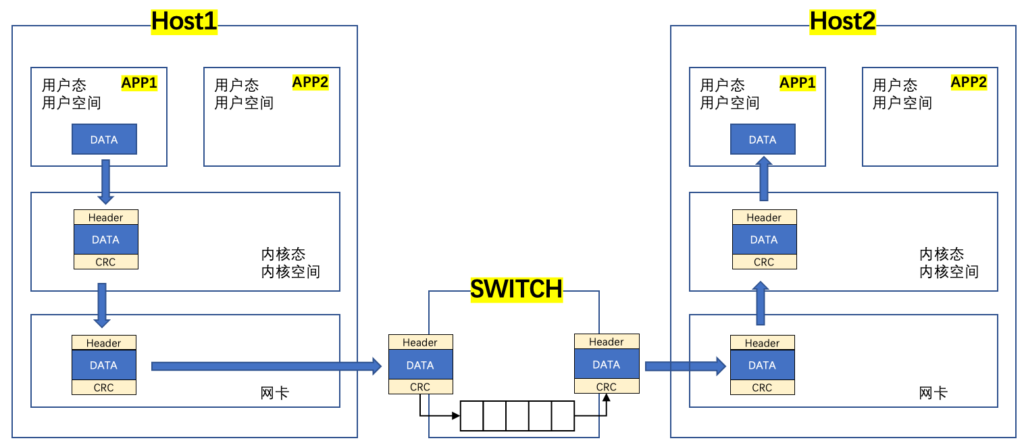
简单说明下:
- 程序在运行时会涉及不同的指令,为了系统安全,不同指令会有不同的级别,高级别需要通过系统调度在内核态使用,而低级别直接用户态调用使用;
- 用户空间是程序启动后系统分配的虚拟内存,通过MMU映射物理内存,每个APP拥有独立的虚拟地址空间;
- 内核空间是供内核使用的虚拟地址空间,内核空间是共享的;
- 应用程序把数据从用户空间拷贝到内核空间,此过程数据本身没有变化,但仍然进行了拷贝,损耗了性能;
- 数据到内存空间后,由内核中的协议栈进行协议封装,发给网卡送出去;
所以之所以TCP单流无法跑满,主要问题应该出在x86架构本身,换句话说就是用户态、内核态之间的数据拷贝损耗,以及CPU性能提升无法追赶上互联带宽的迭代。上面第一篇论文中,是通过3条TCP流才达到100Gbps满速,另外在这篇文章:https://fasterdata.es.net/assets/Papers-and-Publications/100G-Tuning-TechEx2016.tierney.pdf,通过优化,单TCP流可以达到79Gbps。
对于Linux内更详细的网络报文交互过程可以参考《深入理解Linux网络》这本书,讲的还是可以的,通俗易懂。如果只想看内容可以参考作者的Github梳理的原始文章:https://github.com/yanfeizhang/coder-kung-fu。
随着100G网卡的成熟部署,400G网卡也逐渐多起来了,这部分的限制会越来越明显。难道这个限制就没法打破了么?需要单流大带宽的应用要如何解决呢?在x86的架构中,如果使用原生的机制,那确实无法摆脱这个性能损耗,但我们可以通过其他方法来规避这个限制。
DPDK如何解决问题?
之前多种网络设备(交换机,路由器,防火墙等)的数据包处理都是由设备厂商开发的ASIC把控,ASIC可以提供高性能转发。但ASIC的生命周期很长,迭代速度慢,很难快速适配用户的需求,所以需要一款通用设备(处理器+软件),可以媲美ASIC高效的性能,来适配用户不同的需求。因此Intel在2010年开发了DPDK并把其开源,而操作系统采用了兼容性强的Linux。为了避免上面谈到的Linux性能损耗,通过DPDK Bypass内核,直接打通网卡和用户态进行数据交互,从而大大提升了性能。用下面这张图可以说明DPDK是如何工作的,可以跟上面那张图对比看:
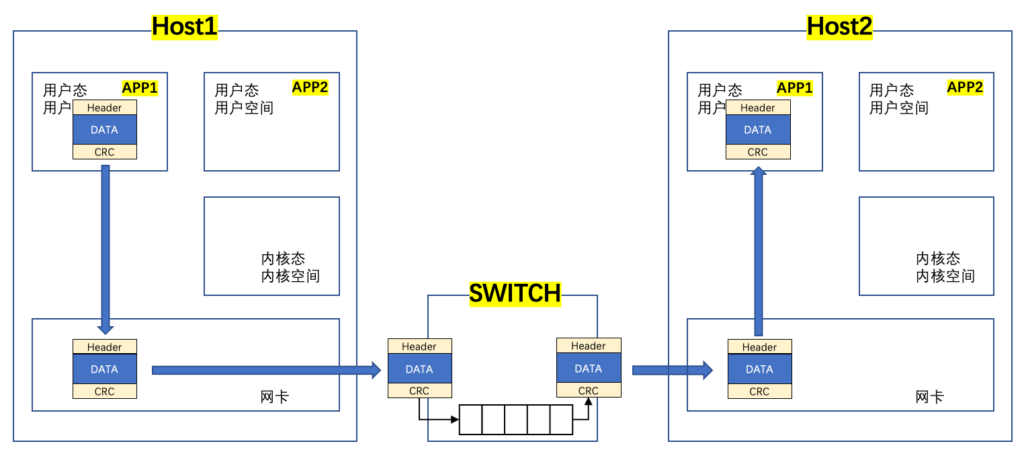
简单说明下:
- 由于Bypass Kernel,对数据封装需要由用户自行适配,如TCP 3次握手等,然后直接发给网卡;
- 由于自行适配协议难度较大,所以可以通过一些其他具有协议层功能的组件同DPDK配合使用,比如使用较多的VPP,其作为应用程序提供完整的协议层,并配合DPDK进行高速转发;
当我们把网卡分配给DPDK后,系统中就看不到这块网卡了,需要通过DPDK命令查看。由于完全Bypass Kernel,导致Kernel被完全隔离,这也是为什么有人说”DPDK is not Linux“的原因。
RDMA如何解决问题?
现在高性能计算都在谈RDMA,那RDMA跟DPDK的主要区别在哪里?为什么他的转发效率更高?可以先看下面这张图:
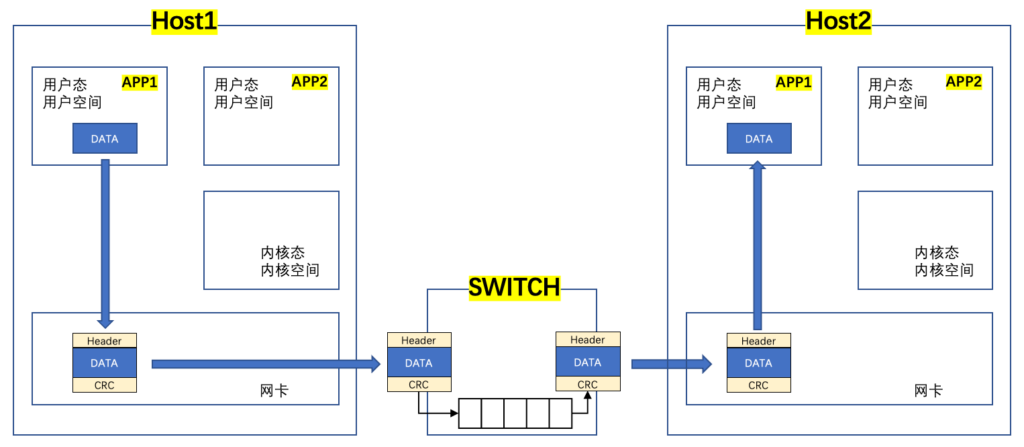
简单说明下:
- 从上图可以看出报文封装和解封装不再由用户自行适配,而是交给网卡去做,这样释放了CPU的资源;
- 当然因为网卡实现了额外的功能,所以对网卡提出了一定的要求;
- RDMA中的协议部分不在这里说明;
XDP如何解决问题?
由于DPDK完全Bypass Linux Kernel,导致Kernel被孤立,通用的安全策略和协议栈均无法被有效利用,因此2016年开发了Linux Kernel自己的高速转发数据面XDP(eXpress Data Path),XDP主要利用Linux原有的eBPF,在Kernel Driver层通过eBPF检索对应的报文并给予特定的Action,用户态的APP可以通过XDP的socket直接调用,已达到高速转发的目的,如下面图所示(注意:这里我没有像上面的图例展示两台Host报文交互过程,因为我看到的大多数XDP的应用案例都是对进来的流量进行处理,而不是APP产生流量通过XDP转发出去。K8s Cilium CNI使用的是eBPF,而不是XDP):
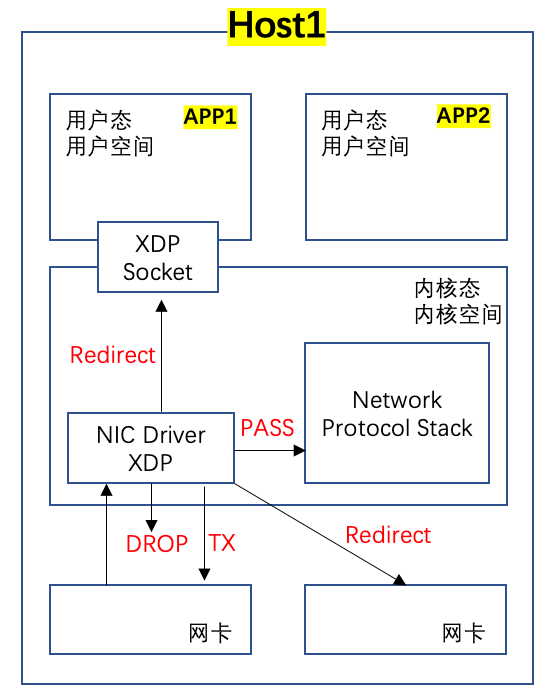
简单说明下:
- eBPF很早就在Linux中支持了,tcpdump就是利用eBPF得以实现的;
- XDP原生Kernel支持,不需要第三方软件;
- XDP是通过Linux Kernel Driver层面实现的,他有几个Action code,如上图红色标记;
- XDP Socket可以同时供用户态和内核态使用,不再需要额外的数据复制;
- 可以去Github上查看下代码实例,更好的理解XDP是如何使用eBPF的:https://github.com/xdp-project/xdp-tutorial/blob/master/packet03-redirecting/xdp_prog_kern.c;
由于XDP提供了不逊于DPDK的高速转发数据平面,同时也更好的利用了Linux Kernel的安全策略和协议栈,这让其在业界得以快速推广,目前XDP主要应用场景有以下几个:
- DDoS防御
- 防火墙
- 业务网关
- 网路统计
- 流量监控
总结及展望
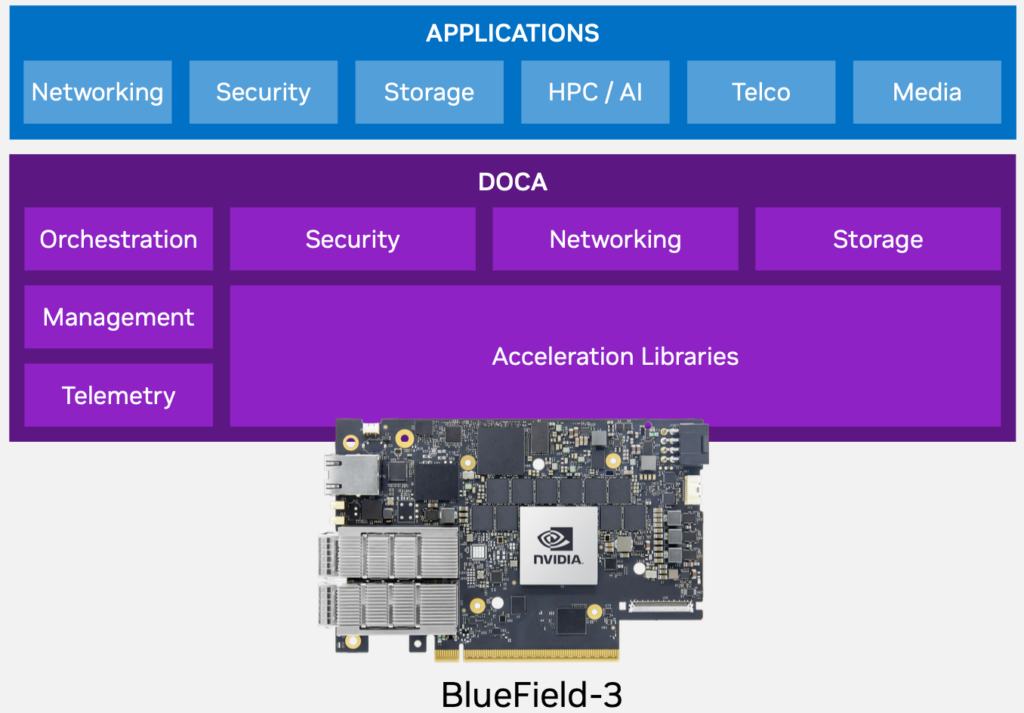
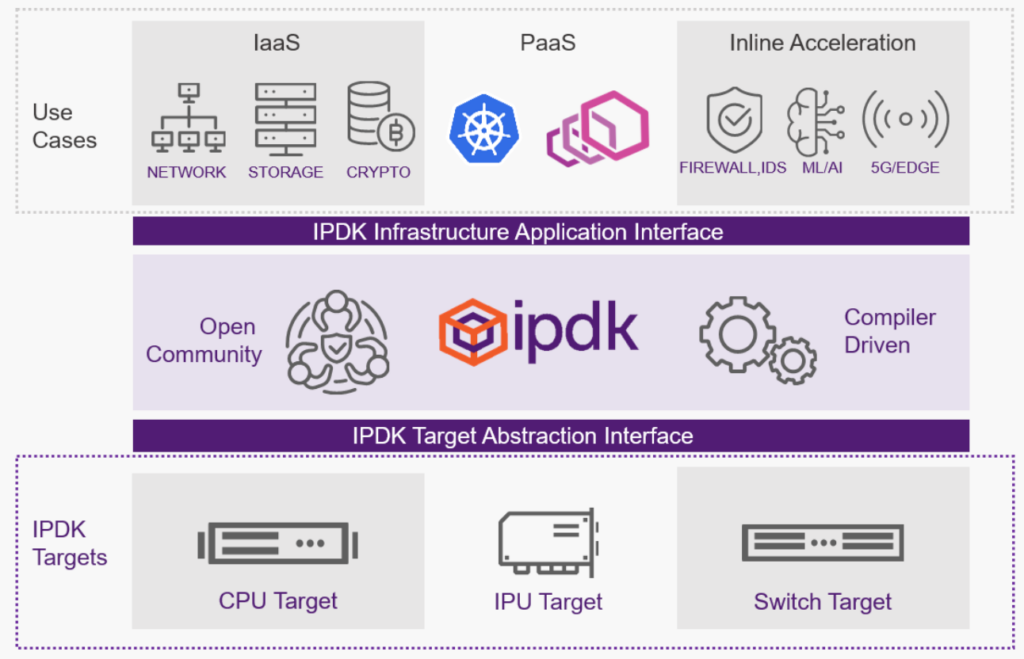
通过上面的分析已经很容易理解瓶颈在哪里,以及解决瓶颈使用的各种技术的主要特点和主要区别。其实从谈到的几种方法中不难看出,这些方法都是围绕如何绕过协议栈,绕过数据低效拷贝,以此提高转发效率。目前业界也越来越多的把之前CPU执行的功能Offload到网卡上,网卡也变得越来越强。就拿Nvida推出的BlueField3 DPU来看,ARM A78已经叠到16颗 + 16GB DDR5(低配版本),所以还有什么是网卡干不了的?。而且不论是Nvida 还是Intel,都在尝试推行智能网卡(这里算是对可编程网卡的总称)自有生态,我的理解应该是类似Sonic的SAI,屏蔽底层,让应用层更容易的去适配,如下图中展示的DOCA和IPDK(更细节的就不在此讨论了):
通过上述这些方法的优化,服务器的性能才能得以释放,也可以缓解互联带宽与CPU性能增长速度不匹配的问题,用下面这张图总结本主题再合适不过了(摘自Understanding Host Network Stack [NetDev 0x15]):
